프로메테우스 샤딩과 타노스
March 2023 (756 Words, 5 Minutes)
프로메테우스 확장과 페더레이션
샤딩 형태의 확장
수직샤딩
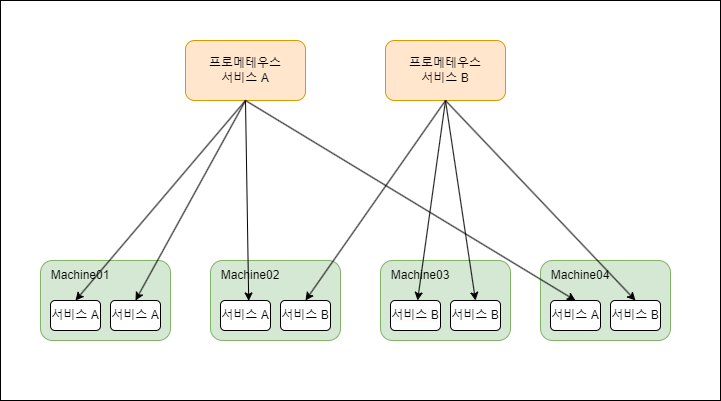 프로메테우스 인스턴스간 격리
프로메테우스 인스턴스간 격리
타깃 묶음에서 많이 사용되는 메트릭의 하위 묶음을 여러 인스턴스로 분할 가능하다
한 인스턴스는 CPU 사용량을, 또다른 인스턴스는 메모리 사용량을 모니터링
각 프로메테우스 인스턴스가 서로 다른 메트릭을 모니터링하면, 각 인스턴스는 해당 메트릭에 대한 모니터링을 더욱 집중적으로 수행
각 인스턴스는 메트릭 수집 및 처리에 더 많은 리소스 (예: CPU, 메모리)를 사용할 수 있음
다만 수직샤딩을 통해 더 작은 단위로 자르는것에 한계가 명확하게 존재한다.
-
자세한 설명
수직 샤딩은 프로메테우스 인스턴스를 다른 인스턴스로 분할하여 각 인스턴스가 서로 다른 서비스나 애플리케이션을 모니터링하는 방식입니다. 이 방법은 인스턴스 간의 격리를 통해 모니터링 범위를 확장할 수 있게 해줍니다. 하지만, 수직 샤딩은 일반적으로 샤딩된 인스턴스 간에 데이터를 공유하지 않기 때문에, 전체 시스템에 대한 통합된 뷰를 제공하지 않습니다.
서로 다른 서비스나 애플리케이션을 개별적으로 모니터링하려는 경우, 수직 샤딩을 사용하여 각 프로메테우스 인스턴스가 특정 서비스를 모니터링하도록 설정할 수 있습니다. 이 방식은 인프라의 격리를 높이고, 각 서비스에 대한 독립적인 모니터링 환경을 제공합니다.
수평샤딩
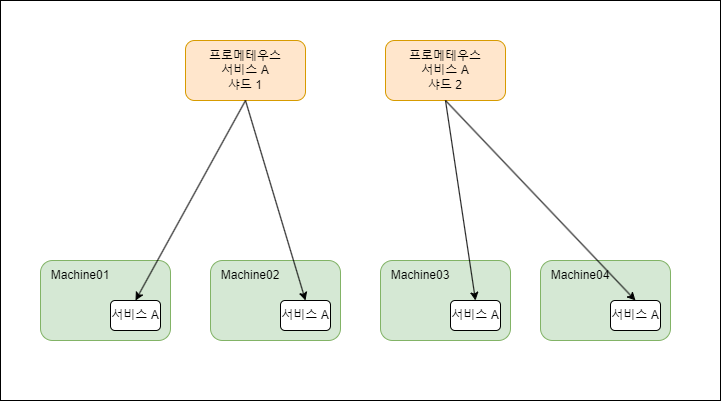
프로메테우스 인스턴스를 여러 개 사용하여 모니터링 대상의 데이터를 분산시키는 방법
이렇게 하여 각 인스턴스의 부하가 줄어들고, 전체 시스템의 확장성이 높아집니다.
이 방법은 대규모 시스템의 모니터링에 적합하며, 샤딩된 인스턴스들은 동일한 데이터를 처리하므로 전체 시스템에 대한 통합된 뷰를 제공할 수 있습니다.
수평 샤딩을 구현하기 위해 “hashmod 레이블 재지정 (relabeling)” 기능을 사용합니다.
이 기능은 프로메테우스의 scrape configuration에서 설정할 수 있으며, 대상 메트릭의 레이블을 기반으로 데이터를 여러 프로메테우스 인스턴스에 분산시키는 역할을 합니다.
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['shard01:9100', 'shard02:9100', 'global:9100']]
relabel_configs:
- source_labels: [__addresss__]
modulus: 2 #Because we're using 2shard
target_label: __tmp_shard
action: hashmod
- source_labels: [__tmp_shard]
regex: 0 #Starts at 0, so this is the first action: keep
대규모 서비스나 애플리케이션을 모니터링하려는 경우, 수평 샤딩을 사용하여 여러 프로메테우스 인스턴스에 데이터를 분산시킬 수 있습니다. 이 방식은 시스템의 부하를 줄이고, 데이터 처리와 저장의 효율성을 높입니다
페더레이션을 이용한 글로벌 뷰
프로메테우스 서버는 /federate에서 제공되는 엔드포인트를 노출
scrape_configs:
- job_name: shards
honor_lables: true
metrics_path: /federate
params:
match[]:
- '{__name__=~"job:.++"}'
static_configs:
- targets:
- shard01:9090
- shard02:9090
프로메테우스의 페더레이션은 프로메테우스 서버 간에 데이터를 집계하고 공유하는 방식입니다.
이 방법은 하위 프로메테우스 서버가 각각의 모니터링 영역을 처리하고, 상위 프로메테우스 서버가 하위 서버에서 데이터를 수집하여 전체 시스템에 대한 통합된 뷰를 제공할 수 있게 해줍니다.
페더레이션은 대규모 시스템의 모니터링 및 분석에 유용하며, 상위 프로메테우스 서버는 경고 및 대시보드와 같은 글로벌 리소스를 처리할 수 있습니다.
전체 시스템에 대한 통합된 뷰가 필요한 경우, 페더레이션을 사용하여 상위 프로메테우스 서버가 하위 서버에서 데이터를 수집하도록 설정할 수 있습니다. 이를 통해 중앙 집중식 모니터링 시스템을 구축하고, 경고 및 대시보드를 한 곳에서 관리할 수 있습니다.
페더레이션 패턴은 여러 프로메테우스 인스턴스 간에 데이터를 집계하고 공유하는 방식입니다.
주로 대규모 시스템의 모니터링 및 분석에 사용되며, 두 가지 주요 패턴이 있습니다: 계층 페더레이션 (Hierarchical Federation), 교차 페더레이션 (Cross-Federation)
계층 페더레이션
계층 페더레이션은 프로메테우스 인스턴스를 계층 구조로 구성하는 방식입니다.
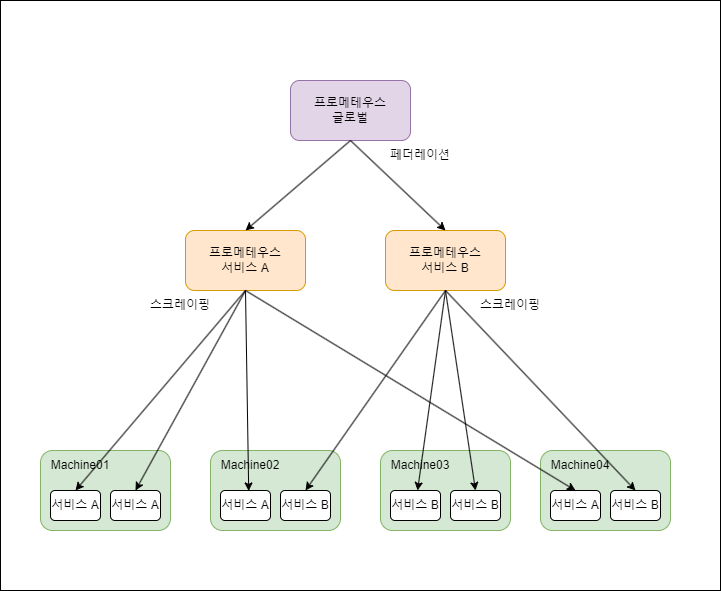
하위 프로메테우스 인스턴스는 각각의 모니터링 영역을 처리하고, 상위 프로메테우스 인스턴스가 하위 인스턴스에서 데이터를 수집합니다. 상위 인스턴스는 전체 시스템에 대한 통합된 뷰를 제공하고, 경고 및 대시보드와 같은 글로벌 리소스를 처리할 수 있습니다.
- 예시
- 팀별 프로메테우스 인스턴스: 각 팀의 시스템 및 서비스를 모니터링하는 각각의 프로메테우스 인스턴스가 있습니다.
- 글로벌 프로메테우스 인스턴스: 모든 팀별 인스턴스에서 선택적으로 중요한 데이터를 수집하고, 조직 전체의 시스템 상태를 모니터링합니다.
교차 페더레이션
교차 페더레이션은 여러 프로메테우스 인스턴스가 서로 다른 인스턴스로부터 데이터를 수집하는 방식입니다.
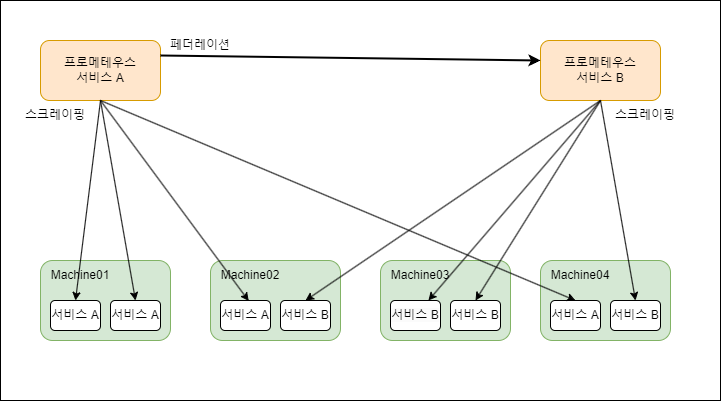 이 방식은 서로 다른 인스턴스 간에 데이터를 공유하고, 특정 서비스나 리소스에 대한 중복 모니터링을 방지할 수 있습니다.
이 방식은 서로 다른 인스턴스 간에 데이터를 공유하고, 특정 서비스나 리소스에 대한 중복 모니터링을 방지할 수 있습니다.
- 예시
- 서비스 A와 서비스 B를 모니터링하는 프로메테우스 인스턴스가 있습니다.
- 서비스 A의 인스턴스는 서비스 B에 관한 정보가 필요한 경우, 서비스 B의 프로메테우스 인스턴스에서 데이터를 수집합니다.
- 반대로, 서비스 B의 인스턴스도 필요한 경우 서비스 A의 인스턴스로부터 데이터를 수집할 수 있습니다.
타노스를 이용한 대규모 프로메테우스 단점 보완
여러개의 샤드 형태가 노출되는경우 메트릭 수집에 문제가 발생한다.
HA형태로 동일한 프로메테우스 인스턴스를 실행하거나, 로드밸런서가 있을때 데이터의 일치성에 문제가 발생할 수 있다.
대시보드가 더 복잡해지기도하며, 해당 문제를 해결하기위해 시작된 프로젝트가 타노스 이다.
타노스 (Thanos)는 프로메테우스를 기반으로 한 모니터링 시스템으로, 글로벌 쿼리, 무제한의 데이터 보존 기간, 그리고 고가용성과 같은 고급 기능을 제공합니다.
사이드카
타노스 사이드카 컨테이너는 프로메테우스 인스턴스와 함께 배포되며, 프로메테우스와 타노스 시스템 간 통합을 담당합니다.
사이드카에서 객체 스토리지로 업로드, 실시간 데이터 전달, 고가용성의 역할을 맡고 있습니다.
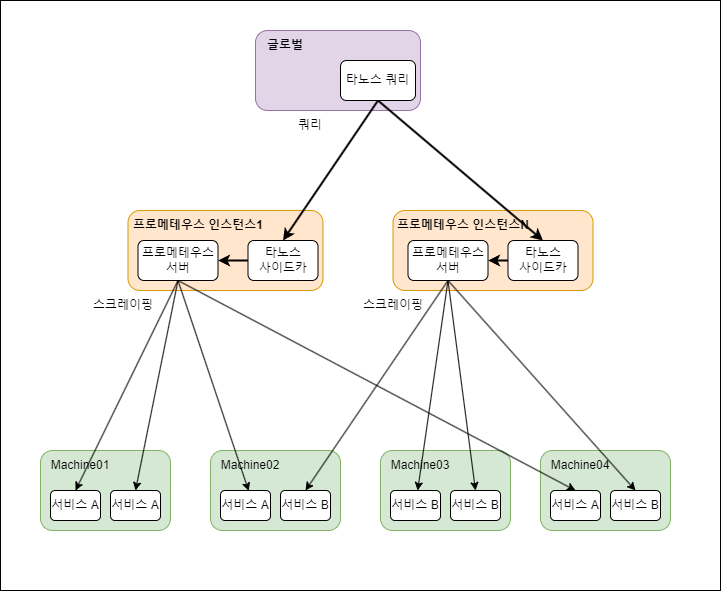
- 글로벌 쿼리: 타노스는 여러 프로메테우스 인스턴스에 걸쳐 데이터를 집계하고 통합된 뷰를 제공하는 글로벌 쿼리 기능을 제공합니다. 이는 프로메테우스의 페더레이션과 유사한 기능이지만, 타노스는 이를 더 간편하게 사용할 수 있는 아키텍처를 제공합니다. 타노스 쿼리 컴포넌트를 사용하여 여러 프로메테우스 인스턴스의 데이터를 쉽게 집계하고 쿼리할 수 있습니다.
- 확장성: 타노스는 프로메테우스의 샤딩과는 다른 방식으로 확장성을 제공합니다. 타노스의 구성 요소들은 분산 시스템으로 설계되어 있어, 서로 다른 프로메테우스 인스턴스의 데이터를 쉽게 공유할 수 있습니다. 이를 통해 사용자는 시스템의 규모를 늘리거나 축소할 때 유연성을 높일 수 있습니다.
- 중복 제거 및 데이터 보존: 프로메테우스의 페더레이션은 중복 데이터를 제거하지 않지만, 타노스는 쿼리 중복 제거를 통해 정확한 데이터를 보장합니다. 또한, 타노스는 프로메테우스 인스턴스에서 생성된 데이터를 외부 객체 스토리지에 저장함으로써, 데이터 보존 기간을 무제한으로 확장할 수 있습니다. 이는 프로메테우스의 로컬 스토리지 제한을 우회하는 방법을 제공합니다.
- 고가용성: 타노스는 프로메테우스 인스턴스의 고가용성을 지원하기 위해 설계되었습니다. 여러 프로메테우스 인스턴스를 사용하여 중복된 데이터를 수집하고, 타노스 사이드카 컨테이너를 통해 이를 객체 스토리지로 전송합니다. 이렇게 함으로써, 단일 인스턴스의 장애로 인한 데이터 손실을 최소화할 수 있습니다.