모니터링
Mont Kim / February 2023 (459 Words, 3 Minutes)
5주차 모니터링
5주차 내용은 메트릭 파이프라인으로 사용되는 대표적인 오픈소스인 프로메테우스와 그라파나에 대해 설명한다.

프로메테우스는
메트릭 수집 및 조회를 하는 대상이다.
app들의 data를 수집해 grafana에게 export 해준다.
그라파나는
데이터 시각화 도구이다.
프로메테우스, Elasticsearch, Loki 등의 DB부터 데이터를 시각화해주는 도구이다.
프로메테우스에서 다양한 클러스터의 데이터들을 한번에 수집해주는
타노스 등과같은 솔루션들도 존재한다.
프로메테우스
프로메테우스의 구조는 다음과 같다.
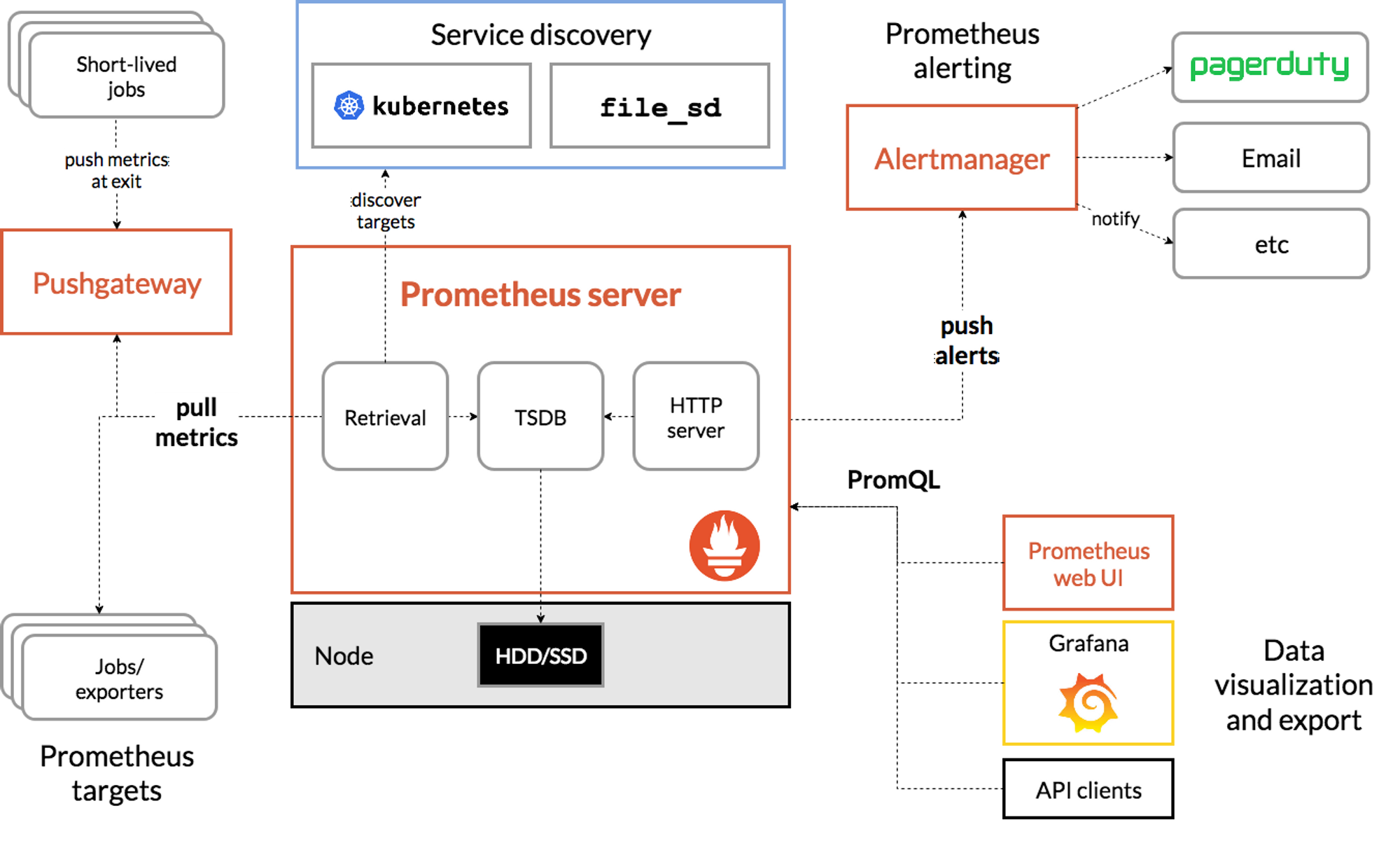
출처 : 프로메테우스 공식 홈페이지 https://prometheus.io/docs/introduction/overview/
다른 메트릭 파이프라인에서도 시계열 DB를 사용한다는 점은 여타 다른서비스들과 동일하다.
설치는 helm 차트를 이용하면 손쉽게 설치가 가능하다
kubectl create ns monitoring
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 -f monitor-values.yaml --namespace monitoring
helm repo add를 진행후, values.yaml 파일에 필요한 정보들을 입력해주면
helm install을 통한 진행이 가능하다.
loadbalancer를 통해 설치되기때문에, 프로비저닝에 시간이 조금 걸린다.
별도로 alb 관련 설정들이 되어있으니, 해당 도메인대로 prometheus.$KOPS_CLUSTER_NAME 주소로 접속하면 확인 할 수 있다.
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
그라파나
그라파나는 프로메테우스등의 TSDB (시계열 데이터베이스) 를 시각화해주는 도구이다.
설치는 helm 차트를통해 alert manager, grafana, promethues를 동시에 설치를했다.
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
해당 링크로 접속 할 수 있다.
| 계정 | 비밀번호 |
|---|---|
| admin | prom-operator |
그라파나에 들어가면 돋보기를 클릭해 대시보드들을 검색하거나
새로 import 할 수 있다.
과제 1 Dashboard 추가하기
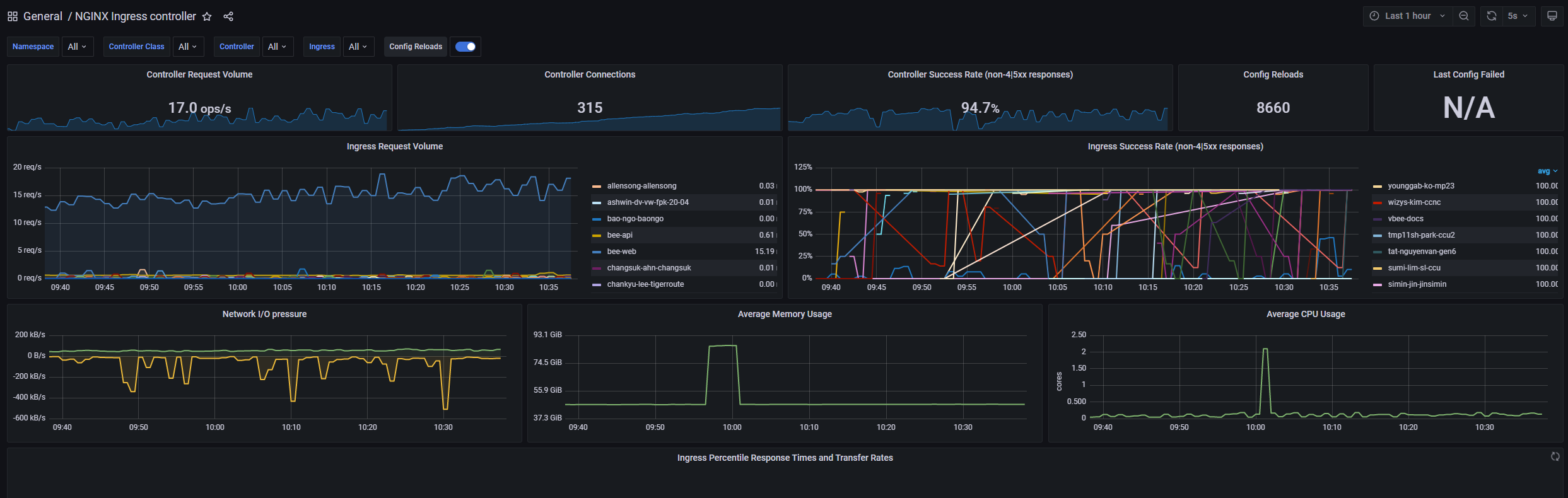
추가할 dashboard는
| [Dashboards | Grafana Labs](https://grafana.com/grafana/dashboards/) |
에서 검색후, json파일을 다운로드후 import 하는 방법과
폐쇄망이 아닌 grafana의경우 dashboard에 업로드 된 ID만으로도 추가가 가능하다.
다음 예시는 ingress nginx controller에 대한 dashboard를 추가한 과정이다.
| [NGINX Ingress controller | Grafana Labs](https://grafana.com/grafana/dashboards/9614-nginx-ingress-controller/) |
과제2 : Nginx Pod 추가하기
Nginx 파드를 배포 후 관련 metric 를 프로메테우스 웹에서 확인하고, 그라파나에 nginx 웹서버 대시보드를 추가 후 확인하시고, 관련 스샷 올려주세요
nginx pod 배포를 진행한다.
helm repo add bitnami https://charts.bitnami.com/bitnami
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
helm install nginx bitnami/nginx --version 13.2.23 -f nginx-values.yaml
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
helm repo add를 진행후, values.yaml 파일을 작성해 install을 진행한다.
서비스 생성 후, 프로메테우스 웹서버에서 nginx 서비스 모니터 추가 확인을 진행한다.
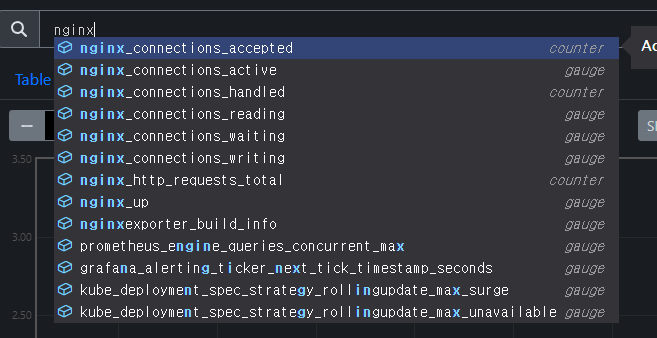
nginx 웹서버 관련 데이터 수집이 되는지 확인을 진행후, query를 해본다.
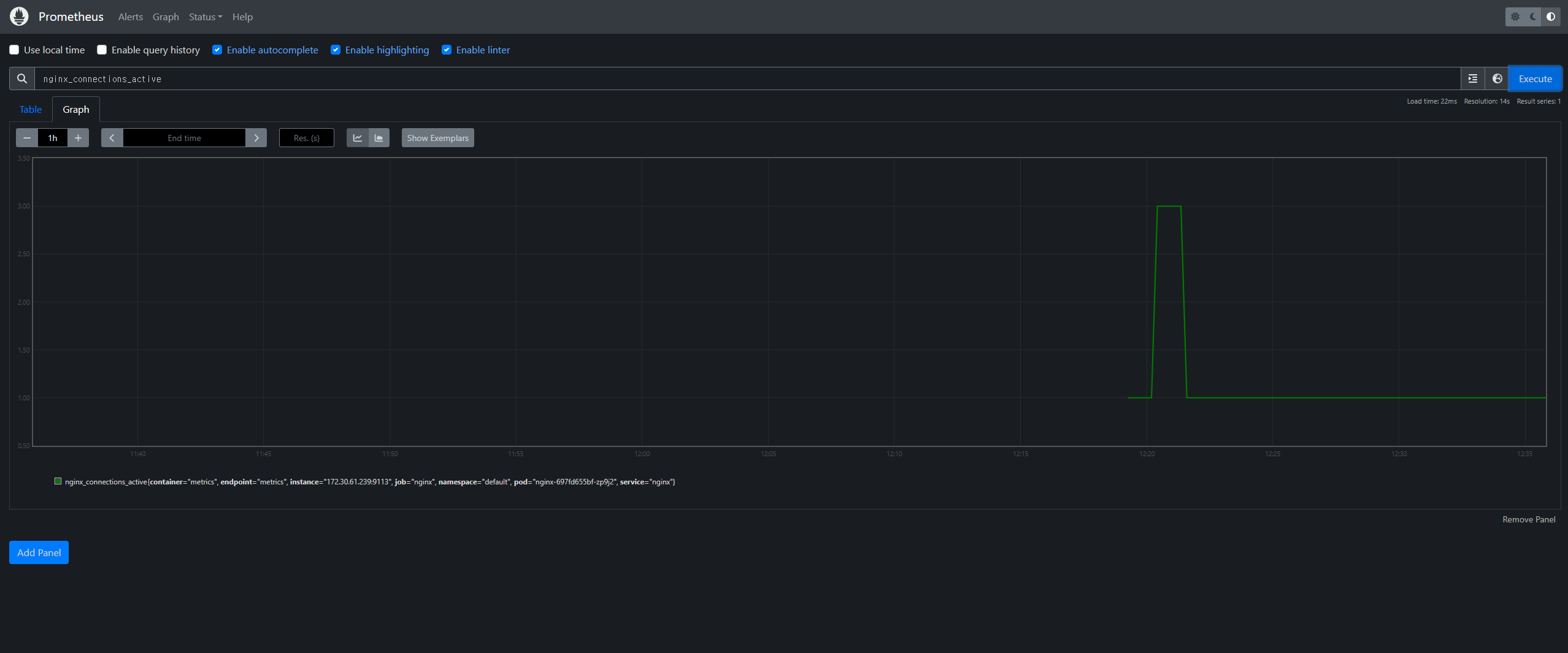
정상적인 query가 된것을 확인후,
그라파나에서 다음 과정을 진행한다.
그라파나 대시보드인 12708을 추가 후 확인해본다.
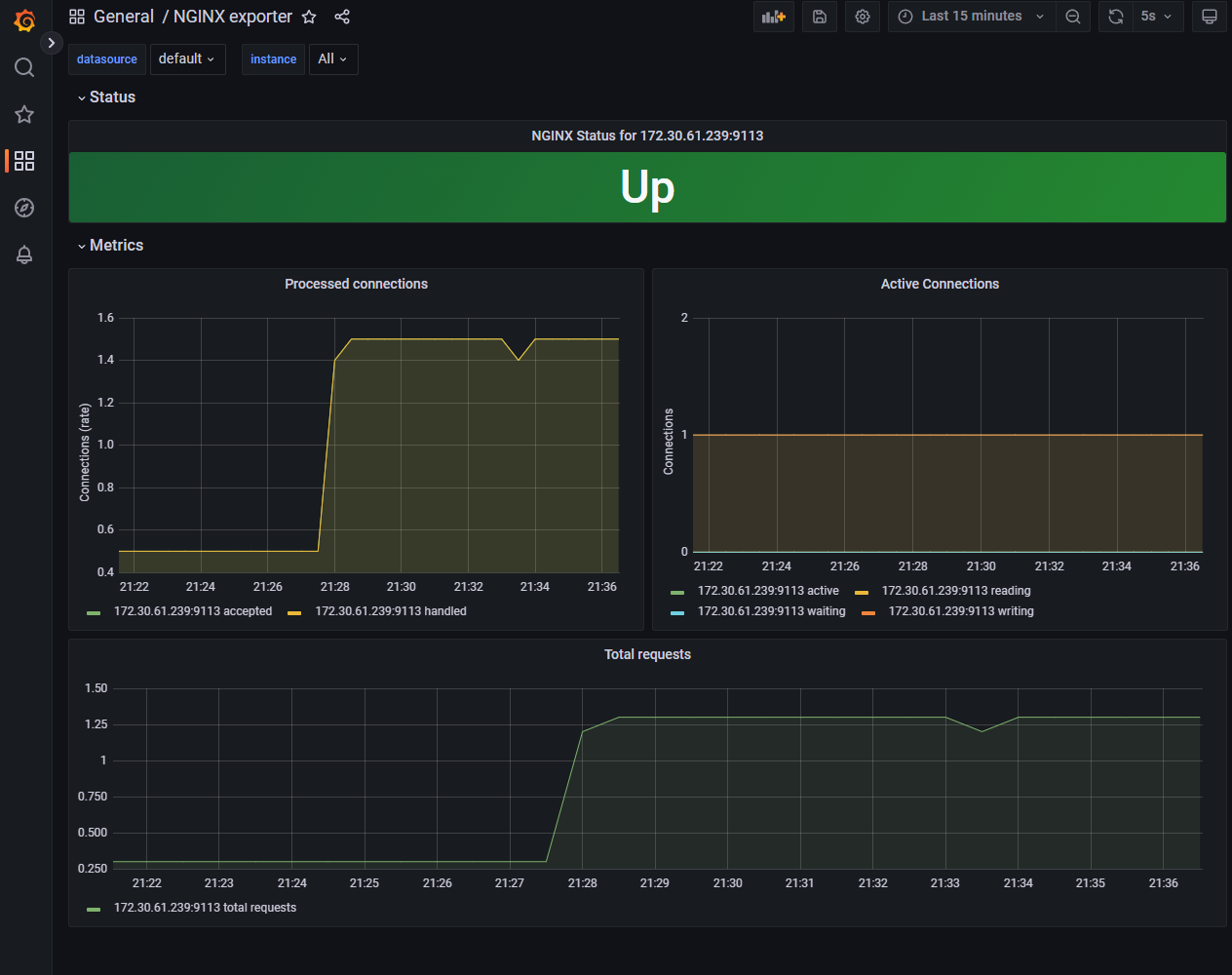
추가한 서비스와
서비스의 데이터들이 프로메테우스, 그라파나 대시보드에서 정상적으로 조회 되는것을 확인 할 수 있다.
메트릭 파이프라인 학습 후기
메트릭 파이프라인에 대해 학습해본 하루였다.
사실 쿠버네티스 운영자라면 사용안해본적이 없기 힘든 오픈소스 솔루션들이다.
데이터독 같은 고급 서비스들도 있지만 논외로 한다.
AWS KRUG (AWS 한국 사용자 모임)의 컨테이너 소모임을 참석해 데이터독 관련 세미나를 들은적이 있었다.
결론은 해당 솔루션이 좋기때문에 써달라는 이야기였지만, 풀어나가는 과정중에
“모니터링 솔루션에서의 알림빈도가 퇴사율과 직접적인 연관성이 있다” 라고 했던 말이 기억난다.
다음주에 배울 경보 / 로깅 에서 더욱 심도있게 다루겠지만, 다시끔 기본적인 구조부터 배울 수 있어서 좋았다.
사실 이번주에 운영중인 쿠버네티스 클러스터에서 네트워크관련 오류가 발생했었다.
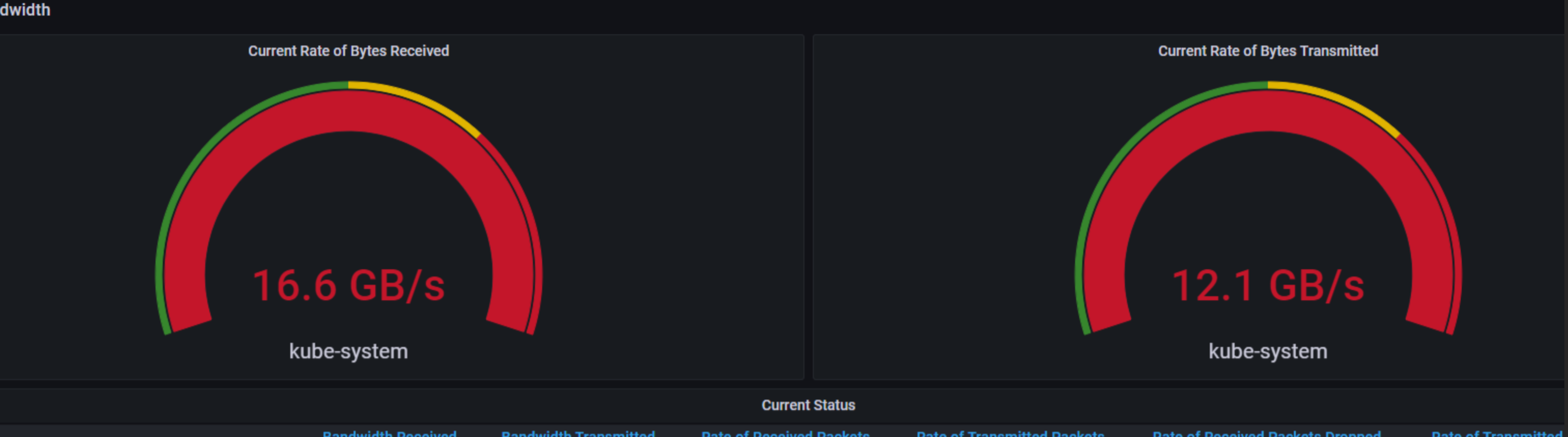
확인을해보니 네트워크 대역폭이 사용량 초과였던거같다.
구체적으론 특정노드에서 네트워크 인터페이스에 장애가 생겨 발생했던 문제였던걸로 밝혀졌지만
이런 정보들을 모니터링 할때는 참으로 유용한거같다.