alertmanager, loki
Mont Kim / February 2023 (1124 Words, 7 Minutes)
6주차 Alert Manger
이번주차에 다룰내용은 5주차에 다뤘던 메트릭 파이프라인에 Alert Manager를 추가한
KOPS로 클러스터를 프로비저닝후, LoadBalancer 생성권한과 ExternalDNS 권한을 부여후 클러스터 정보를 업데이트한다.
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AllowExternalDNSUpdates --role-name nodes.$KOPS_CLUSTER_NAME
kops edit cluster
spec:
certManager:
enabled: true
awsLoadBalancerController:
enabled: true
externalDns:
provider: external-dns
metricsServer:
enabled: true
kubeProxy:
metricsBindAddress: 0.0.0.0
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster --yes
이번 업데이트내용은 master 인스턴스가 새로 생성되기때문에, 새로생긴 master 인스턴스의 public ip를 route53에서 수정해주어야한다.
프로비저닝까지 약 15분정도 소요된다.
프로메테우스 스택 설치하기
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
# helm chart 추가
kubectl create ns monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# helm chart values.yaml 파일 수정
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 -f monitor-values.yaml --namespace monitoring
프로메테우스, 그라파나, alertmanger 확인
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
echo -e "Alertmanager Web URL = https://alertmanager.$KOPS_CLUSTER_NAME"
프로메테우스, 그라파나의 경우 전 시간에서 다루었기때문에 따로 넘어간다.
Alert Manager
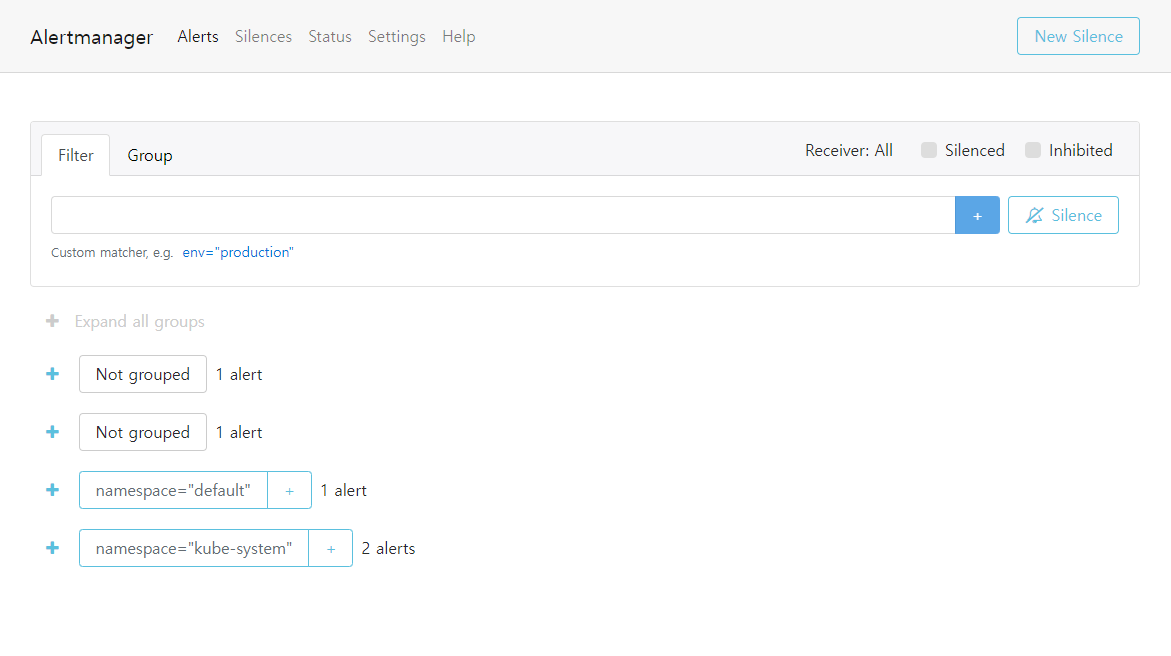
Alert 경고 : 시스템에 문제가 발생할경우 프로메테우스가 전달한 경고메세지의 목록을 확인한다.
Silence : 계획된 작업을 할 때, 일정기간동안 메세지를 받지않음
AlertManger Dashboard
Karma를 이용하여 컨테이너로 Dashboard를 올린다
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
접속주소 확인
echo -e "karma Web URL = http://$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)"
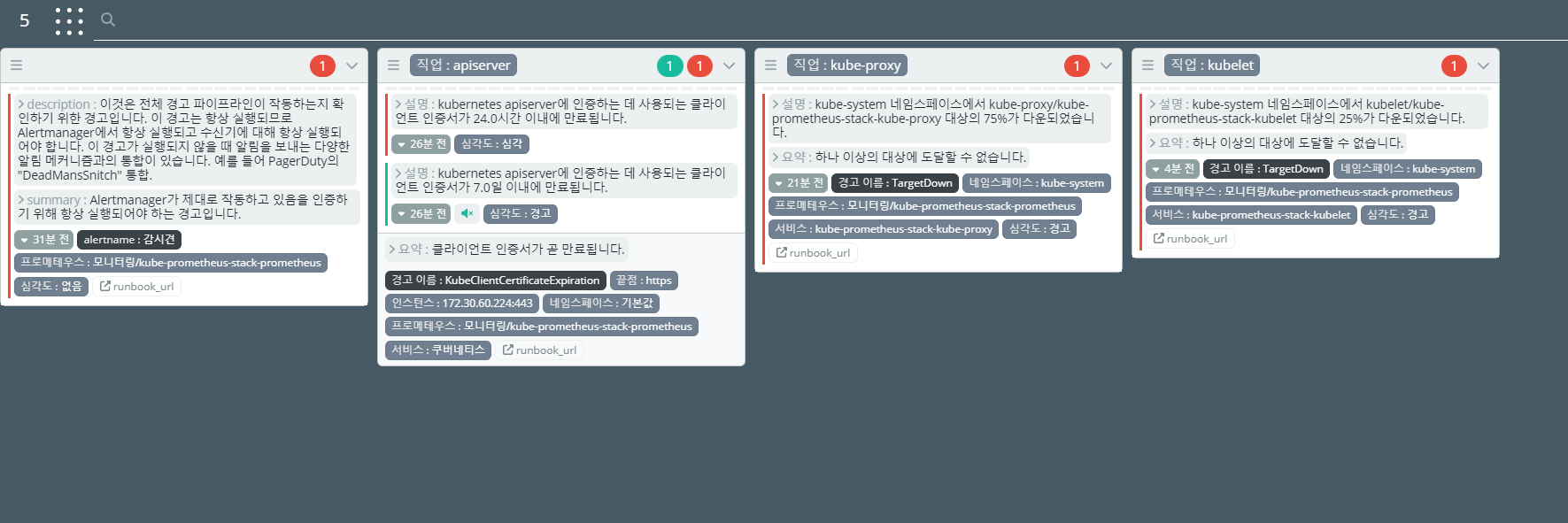
alert manager에서 push 하는 메세지를 slack에 등록을 진행한다.
slack 채널의 설정 → 통합 → 앱 → 앱추가에 “incoming Webhooks”를 추가한다.
웹훅을 추가하고나면 채널의 고유 webhook url이 생성된다.
이 url이 노출될경우 외부에서 슬랙 메세지를 날릴수있으니 보안에 유의하도록 한다.
webhook curl test
curl -X POST --data-urlencode "payload={\"channel\": \"#monitoring\", \"username\": \"webhookbot\", \"text\": \"이 항목은 #개의 monitoring에 포스트되며 webhookbot이라는 봇에서 제공됩니다.\", \"icon_emoji\": \":ghost:\"}" \
https://hooks.slack.com/services/@@@@@@@/#########/$$$$$$$$$$$$

정상적인 응답이 온것을 확인했으니 alert manager 등록을 해본다.
cat <<EOT > ~/alertmanager-slack.yaml
alertmanager:
config:
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/@@@@@@@/#########/$$$$$$$$$$$$'
route:
group_by: ['job'] # namespace
group_wait: 10s
group_interval: 1m
repeat_interval: 5m
receiver: 'slack-notifications'
routes:
- receiver: 'slack-notifications'
matchers:
- alertname =~ "InfoInhibitor|Watchdog"
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#webhook'
send_resolved: true
title: '[] '
text: |
Description:
EOT
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.0.0 --reuse-values -f alertmanager-slack.yaml --namespace monitoring
위와같이 프로비저닝할경우 Alert Manager에서 Silence 기능을 사용할때 오류가 있다.
pod에 레이블을 직접 추가해 kube-controller-manager, kube-scheduler 장애 이슈를 해결한다.
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-controller-manager -oname) -n kube-system component=kube-controller-manager
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-scheduler -oname) -n kube-system component=kube-scheduler
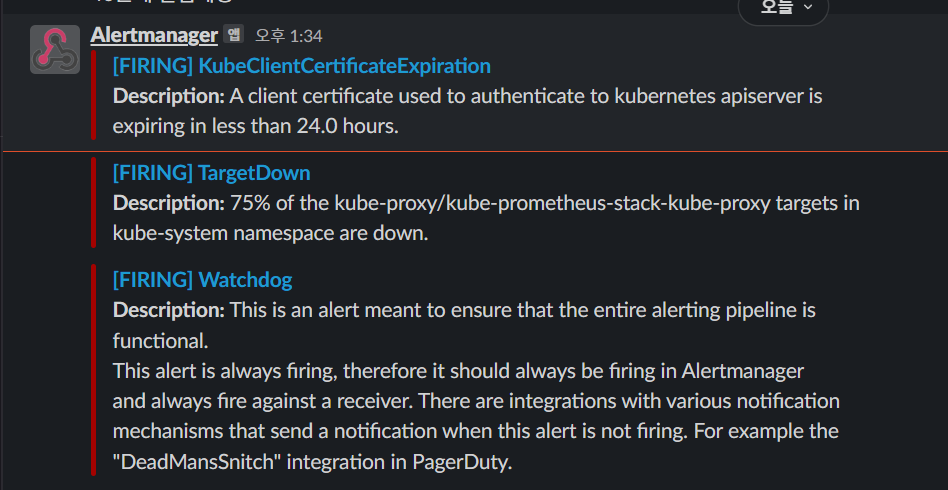
슬랙 메세지를 확인해보면 기본적인 알림들이 오는것을 확인 할 수 있다.
하지만 무의미한 알림은 스트레스소요밖에 안되니, 장애알람은 최소한으로 다이어트시키는것이 비용효율적일것이라고 생각이 된다.
proumetheusrule 확인하기
kubectl get prometheusrules -n monitoring -o json | grep TargetDown -B1 -A11
{
"alert": "TargetDown",
"annotations": {
"description": "% of the / targets in namespace are down.",
"runbook_url": "https://runbooks.prometheus-operator.dev/runbooks/general/targetdown",
"summary": "One or more targets are unreachable."
},
"expr": "100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) \u003e 10",
"for": "10m",
"labels": {
"severity": "warning"
}
},
과제1 : prometheus rule 수정하기
수정된 rule을 helm차트의 values.yaml로 수정해 apply하거나, prometheusrules 라는 타입의 데이터를 직접 수정하는 방법이 존재한다.
kubectl edit prometheusrules kube-prometheus-stack-general.rules -n monitoring
추가할 alert의 종류는 해당 링크에서 검색후 추가한다.
- alert: NodeFilesystemAlmostOutOfSpace-20
annotations:
description: Filesystem on at
has only % available space left.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodefilesystemalmostoutofspace
summary: Filesystem has less than 20% space left.
expr: |-
(
node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 20
and
node_filesystem_readonly{job="node-exporter",fstype!=""} == 0
)
for: 10m
labels:
severity: warning
해당 코드를 추가한다.
해당 규칙은 노드의 사용량이 80%가 넘을때 생기는 규칙이므로, 인위적으로 노드의 disk 사용량을 80% 이상으로 맞춰준다.
sudo fallocate /var/100g-l 100g
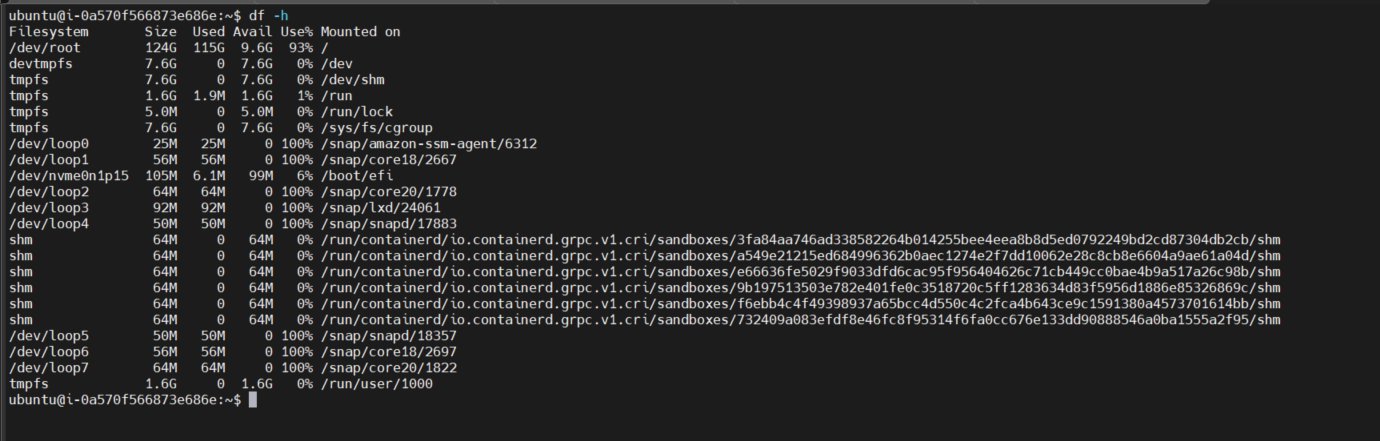
주의 : fallocate에서 너무많은 disk를 쓰기할경우 쿠버네티스 pod들에서 eviction이 발생한다.
아마 리눅스 시스템의 5~7%정도는 root계정이 고유하게 사용하는 공간으로 할당되어 컨테이너를 실행시킬 수 없는 환경이 되는것으로 추정된다.
slack 메세지를 확인해보면 추가된 규칙에 따른 메세지가 왔음을 확인 할 수 있다.
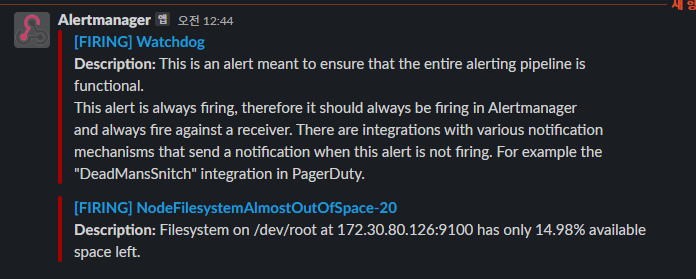
과제3 : 새로운 규칙 추가하기 2
해당 홈페이지에서 도움이 될만한 정책을 찾아본다.

최근에 운영중인 클러스터에 스토리지를 NetApp의 장비를 사용하는데,
이유는 알 수 없지만 응답속도가 굉장히 늦어지는 현상이 발생하는것을 확인했다.
따라서 disk read / write 응답속도가 늦어지면 알림을 받는 규칙을 추가하고자 한다.
kubectl edit prometheusrules kube-prometheus-stack-general.rules -n monitoring
- alert: HostUnusualDiskWriteLatency
expr: rate(node_disk_write_time_seconds_total[1m]) / rate(node_disk_writes_completed_total[1m]) > 0.1 and rate(node_disk_writes_completed_total[1m]) > 0
for: 2m
labels:
severity: warning
annotations:
summary: Host unusual disk write latency (instance )
description: "Disk latency is growing (write operations > 100ms)\n VALUE = \n LABELS = "
수정을 완료하고나면 prometheus 웹에서 해당 이벤트를 조회해 볼 수 있다.
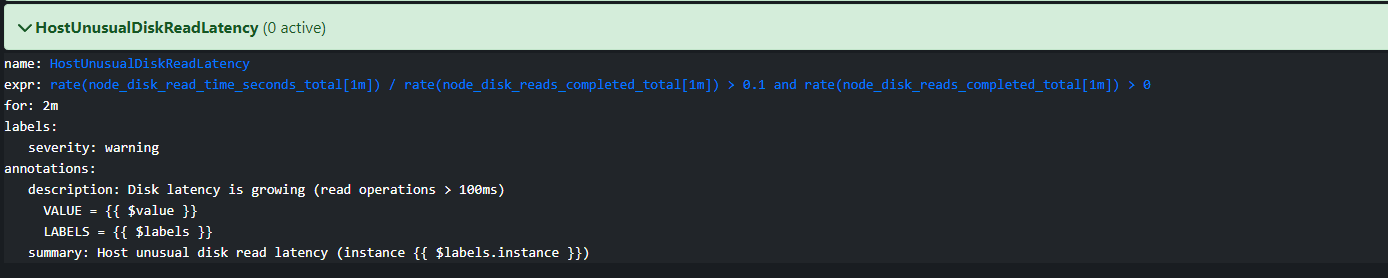
로그 파이프라인
5주차와 6주차에 걸쳐 메트릭 파이프라인에 대해 공부했다
ELK 또는 EFK등의 로그 파이프라인이 가장 대표적이다.
(Elasticsearch - Logstath - Kibana) / (Elasticsearch - FluentD - Kibana)
하지만 PLG스택을 사용할경우 훨씬 가볍다
https://grafana.com/docs/grafana/latest/alerting/
Promtail + Loki + Grafana 을 이용한 PLG 스택을 다뤄볼 예정이다.
Promtail : Daemonset으로 실행되어 각 로그에 로그 중앙로키 서버에 전달
Loki : LogQL을 이용해 조회가 가능하며, 그라파나 웹을 통해 조회 할 수 있다.
Loki 설치
kubectl create ns loki
helm repo add grafana https://grafana.github.io/helm-charts
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
Promtail 설치
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
EOT
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
nginx pod을 테스트로 생성해 로그를 찍어보도록 한다.
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx --version 13.2.27 -f nginx-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
CLB로 생성한 nginx pod은 생성후 약 5분정도 기다려야한다.
nginx.mont-kim.com 으로 접속을 시도해보고, 접속이 정상적으로 된다면, while문을 통해 주기적으로 접속시도를 해보고, 그 로그정보를 수집해보는 과정을 거쳐본다.
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done
과제2 : LogQL 사용법 익히기
그라파나에서 Loki Data 수집하기
Grafana → Configuration → Datasource : 데이터 소스 추가 → Loki
- HTTP URL : http://loki-headless.loki:3100 ⇒ Save & Test
이제 Grafana에서 Loki를 이용한 데이터수집이 가능한상태다.
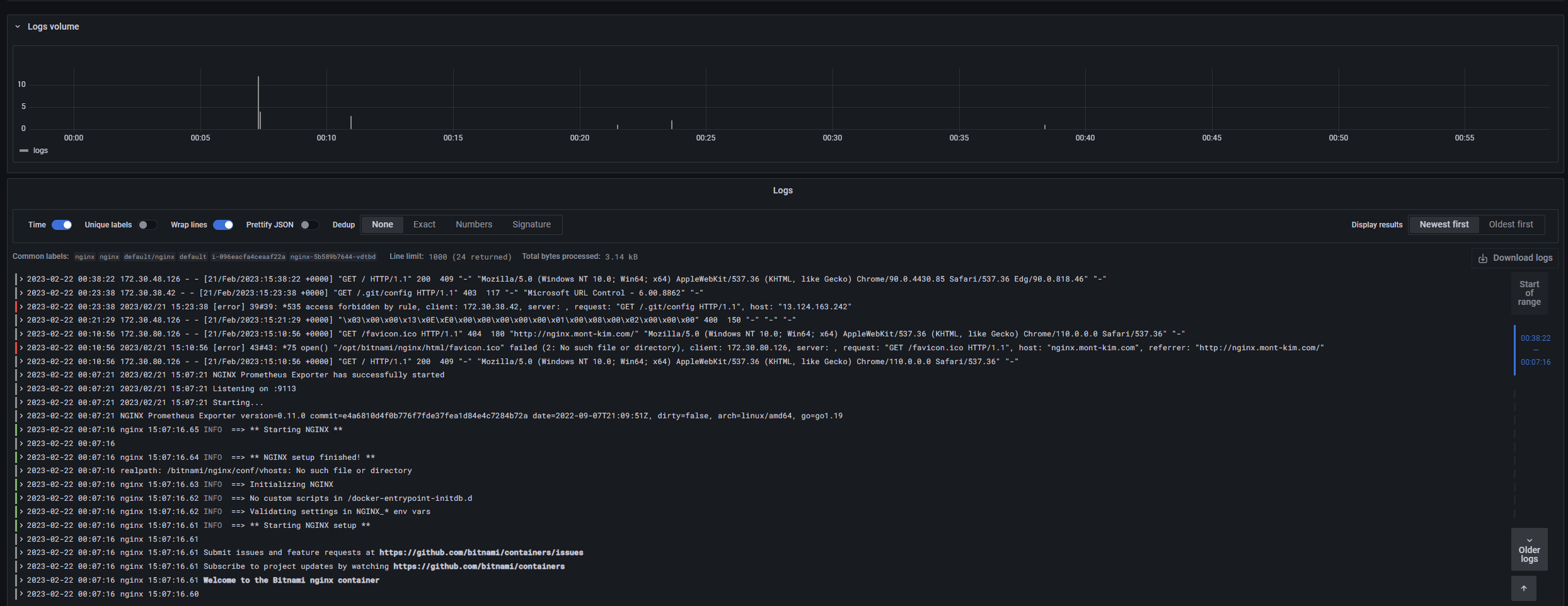
log 데이터가 수집됨을 확인했다
로그데이터만 확인한다는데선 Kibana에서 ElasticSearch로 데이터를 뽑아보는것보단 훨씬 간편한거같다.
추가적으로 고객사의 클러스터를 운영중인데, 커뮤니케이션을 Slack → MSTeams 로 이관을해 해당 코드도 같이구현을해서 문서로 정리해보고싶었다.
고객사 선임님도 실패하셨는데, 개인환경에서 먼저 성공을 한 뒤에 반영을 하는게 좋을거같다.
MS Teams alert messenger 성공하면 다시 써야겠다