Llama2 Mac에서 실행하기
August 2023 (296 Words, 2 Minutes)
사용자 환경은 mac studio 환경을 기준으로 작성되었습니다.
1. 환경변수 설정
사용자 환경에 접속한뒤에, 환경변수 설정을 진행합니다.
경로는 기본경로 에 .zshrc 파일을 새로 생성해주면 됩니다.
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/opt/homebrew/Caskroom/miniforge/base/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/opt/homebrew/Caskroom/miniforge/base/etc/profile.d/conda.sh" ]; then
. "/opt/homebrew/Caskroom/miniforge/base/etc/profile.d/conda.sh"
else
export PATH="/opt/homebrew/Caskroom/miniforge/base/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
export PATH=/opt/homebrew/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/opt/python/libexec/bin:$PATH
alias ll="ls -al"
alias python="python3"
해당 코드를 넣은 후, 재접속을 하거나
source ~/.zshrc
명령어를 이용해 접속환경의 환경변수 설정을 적용합니다.
적용하고나면 앞에 (base) 와 같은 현재 환경이 적용된것을 확인 할 수 있습니다.
2. Llama 2 모델 다운로드
llama2를 구동하기전에, llama2 데이터셋 다운로드가 필요합니다.
에 접속하여 Downloadthe Model을 선택후, 몇가지 정보를 입력하면 메일로 다운로드가 가능하다는 내용을 보내줍니다.
등록이 완료되었으면, 다운로드를 조금 더 쉽게 할 수 있게, llama project를 clone 해서 모델을 다운로드합니다.
git clone https://github.com/facebookresearch/llama.git
해당 프로젝트 내의 download.sh 파일을 실행하여 위에 등록했던 이메일로 날라온 토큰 입력하면, 다운로드 할 모델을 선택하게 됩니다.
다운받으실 모델명을 선택하면 다운로드가 진행됩니다.

해당파일은 별도로 다운로드 받지 않아도 로컬 테스트 환경의 /Users/Shared/llama 폴더 밑에 llama-2-13b-chat 과 llama-2-7b-chat 모델이 다운로드 되어있습니다.
3. Llama 2 실행 프로젝트
맥에서 c++기반으로 별도 종속성 없이 실행 가능하게 해주는 프로젝트가 존재합니다.
3.1 다운로드
git clone https://github.com/ggerganov/llama.cpp.git
3.2 Build
llama.cpp 프로젝트 다운로드 후, 해당 환경에 맞는 빌드를 진행해야 합니다.
빌드는 build-metal 과정을 이용하며 두가지 설치방법이 가능합니다
- Using
make:
LLAMA_METAL=1 make
- Using
CMake:
mkdir build-metal
cd build-metal
cmake -DLLAMA_METAL=ON ..
cmake --build . --config Release
3.3 Convert
2 항목에서 다운로드 받았던, 또는 기존에 다운로드 받아져 있는 Llama2 데이터셋을 llama.cpp 형식에 맞게 convert를 합니다.
python3 convert.py --outfile models/7b-chat-f16.bin --outtype f16 /Users/Shared/llama/llama-2-7b-chat
위 예시는 shared 폴더에 있는 7b-chat 데이터셋을 변환하는 과정입니다.
3.4 실행
3.3에서 convert한 파일을 구동하는 mac의 환경에 맞게 실행합니다.
mac에서 gpu를 사용하는 옵션을 추가해 사용한 명령어입니다.
./main -m models/7b-chat-f16.bin -n 1024 -ngl 1 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt
interactive mode로 실행해, 대화형으로 원하는 질문을 할 수 있는 환경이 실행됩니다.

최초에 명령어를 실행 할 때, gpu 관련 에러가 발생하지 않는다면 gpu를 온전히 모두 사용한 상태로 Llama 모델이 실행된 것입니다.
build 과정에서 build-metal 아닌 다른 build를 할경우 gpu support이 불가능 할 수 있습니다.

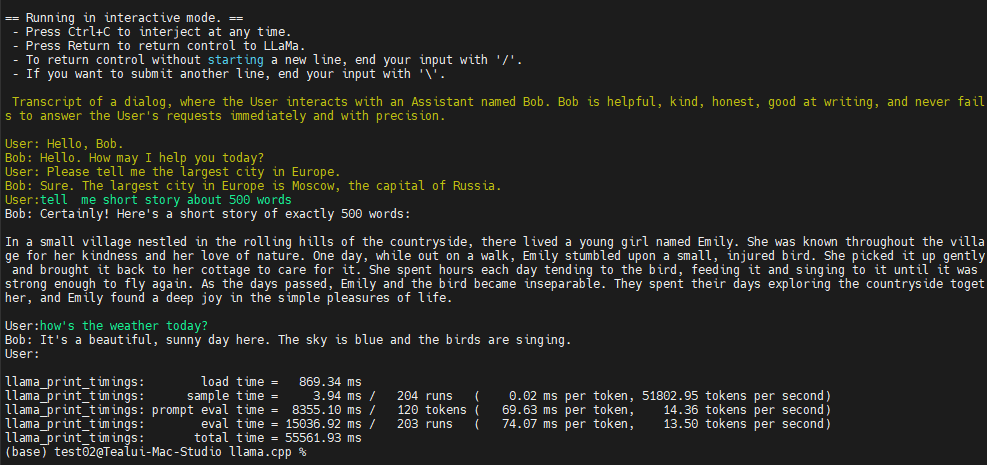
정상적으로 실행이 된다면 User : 항목에서 원하는 질문을 하며 대화를 할 수 있고
Ctrl + C 를 하면 대화를 종료 할 수 있습니다.
종료가 될 때 “tokens per second” 로 현재 실행환경에서 연산 가능한 속도를 확인 할 수 있습니다.