Llama2 Kubernetes에서 실행하기
August 2023 (623 Words, 4 Minutes)
Llama2 on Kubernetes
Kubernetes 환경에서 Nvidia GPU를 이용해 Llama2를 이용한 추론을 하는 과정을 담았습니다.
해당 문서에선 사용 환경을 이해하기 위해 Base Ubuntu 이미지 부터 환경을 구성합니다.
Llama 구동을 위한 컨테이너 만들기
우선 컨테이너 생성에 앞서, 호스트 노드에 설치되어 있어야 하는 nvidia 드라이버 정보입니다.
- 호스트 : Nvidia-smi와 nvidia-docker가 설치되어 런타임으로 지정되어 있어야 합니다.
- 컨테이너 : CUDA Toolkit이 설치된 이미지를 사용하거나, 직접 설치해야 합니다. CUDA 런타임 뿐만이 아니라, NVIDIA CUDA Compiler가 설치된 devel 이미지를 사용합니다
nvidia/cuda:12.2.0-devel-ubuntu20.04 이미지를 이용하여 nvcc 를 이용합니다.
llama를 설치, 사용하기위해 이용하는 deployment 입니다.
클러스터안에 가용한 nvidia gpu가 있는 상태에서만 구동이 가능한 리소스입니다.
cuda 12.2.0 버젼을 이용하기때문에 맞는 nvidia 드라이버가 필요합니다.
글 작성 기준으로 nvidia-driver-530은 12.1 버젼까지밖에 지원하지 않기때문에 nvidia-driver-535로 업데이트를 진행했었습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda-deployment
spec:
replicas: 1
selector:
matchLabels:
app: cuda-llama
template:
metadata:
labels:
app: cuda-llama
spec:
containers:
- name: cuda-llama
image: nvidia/cuda:12.2.0-devel-ubuntu20.04
imagePullPolicy: IfNotPresent
command:
- "/bin/sleep"
- "3650d"
resources:
limits:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: "1"
requests:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: "1"
volume 생성이 가능하다면, deployment의 volume과 pv, pvc를 생성합니다.
쿠버네티스 pod은 이미지로 컨테이너를 생성하고 프로세스가 없으면 계속 재시작을 하기 때문에 sleep 명령어를 넣어두었습니다.
각자 작업환경에 따라 다르기 때문에 위 코드에서는 삭제했지만, 제가 구축해둔 환경의 경우 다음과 같은 볼륨을 생성합니다
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda-deployment
spec:
replicas: 1
selector:
matchLabels:
app: cuda-llama
template:
metadata:
labels:
app: cuda-llama
spec:
containers:
- name: cuda-llama
image: nvidia/cuda:12.2.0-devel-ubuntu20.04
imagePullPolicy: IfNotPresent
command:
- "/bin/sleep"
- "3650d"
resources:
limits:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: "1"
requests:
cpu: "4"
memory: "16Gi"
nvidia.com/gpu: "1"
volumeMounts:
- mountPath: /root
name: cuda-storage
nodeSelector:
kubernetes.io/hostname: node2
volumes:
- name: cuda-storage
persistentVolumeClaim:
claimName: cuda-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cuda-pvc
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
위의 코드대로 생성한 pod에 들어가 작업을 마저 진행해봅니다.
패키지 script
해당 이미지를 바탕으로 생성한 컨테이너에서 사용하기 위한 패키지들을 설치합니다.
별도로 이미지를 만들지 않는한, 컨테이너가 재 시작되면 패키지 설치정보가 삭제되니 별도 script로 제작했습니다.
#!/bin/bash
apt update && apt install -y wget build-essential curl make vim git expect
apt install -y python3 python3-pip
nvcc --version
Llama 데이터 다운로드하기
llama2를 구동하기전에, llama2 데이터셋 다운로드가 필요합니다.
에 접속하여 Download the Model 선택 후 정보를 입력하면 입력했던 메일로 다운로드에 필요한 토큰을 보내줍니다.
이후에 llama project를 clone 해서 모델을 다운로드합니다.
git clone https://github.com/facebookresearch/llama.git
해당 프로젝트 내의 download.sh 파일을 실행하여 위에 등록했던 이메일로 날라온 토큰 입력하면, 다운로드 할 모델을 선택하게 됩니다.
다운받으실 모델명을 선택하여 다운로드를 진행니다.

3. Llama 2 실행 프로젝트
Llama를 구동가능하게 c++로 구현한 프로젝트가 있습니다.
mac의 gpu환경 뿐만아니라, nvidia의
3.1 다운로드
git clone https://github.com/ggerganov/llama.cpp.git
3.2 Model 변환
2 에서 다운로드 받았던 llama-7b-chat 모델을 변환하는 작업입니다.
python3 -m pip install -r requirements.txt
python3 convert.py --outfile models/7b-chat-f16./main -m models/7b-chat-f16.bin -n 128 --n-gpu-layers 20 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt.bin --outtype f16 ../llama/llama-2-7b-chat
3.3 Build
llama.cpp 프로젝트 다운로드 후, 해당 환경에 맞는 빌드를 진행해야 합니다.
nvidia를 이용하는 빌드는 cublas 과정을 이용하며 make와 cmake를 이용한 빌드를 지원합니다.
위에 설치 script 항목에서 make build를 위한 패지키를 설치했기 때문에 make build를 진행합니다.
- Using
make:
make LLAMA_CUBLAS=1
3.4 실행
3.3에서 convert한 파일을 구동하는 mac의 환경에 맞게 실행합니다.
mac에서 gpu를 사용하는 옵션을 추가해 사용한 명령어입니다.
./main -m models/7b-chat-f16.bin -n 128 --n-gpu-layers 20 --repeat_penalty 1.0 --color -i -r "User:" -f ./prompts/chat-with-bob.txt
interactive mode로 실행해, 대화형으로 원하는 질문을 할 수 있는 환경이 실행됩니다.
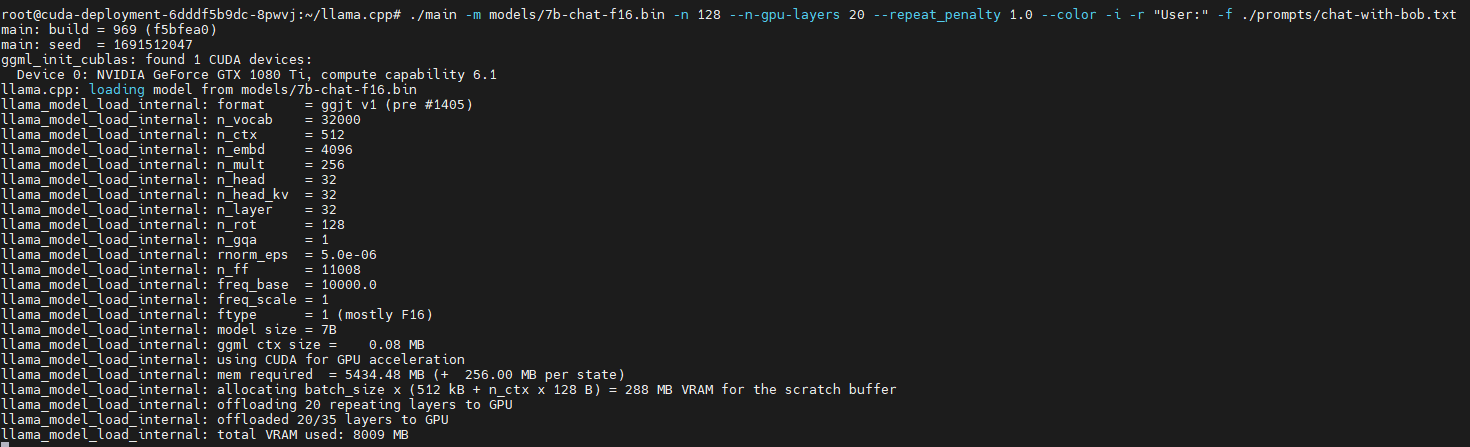
명령어를 실행하면 관련 파라미터들이 보입니다.
해당환경은 1080Ti를 이용해 모델을 구동시켰고, using CUDA for GPU acceleration 가 있는것을 보아 정상적으로 CUDA 가속을 이용하고있다는것을 알 수 있습니다.
최소 6기가 이상의 자원이 필요하고, gpu layer를 20으로 설정했기 때문에 약 8기가의 Vram을 필요로 하는것을 볼 수 있습니다.
1080Ti 2장을 이용할때는 gpu layer를 증가시켜 사용하는 총 Vram을 증가시켜 더 큰모델을 불러오거나, 성능을 향상 시킬수 있습니다.
제 다른환경으로 RTX 3090을 사용하는 노드도 있습니다. 이 gpu를 할당하면 gpu-layer를 훨씬 증가시켜 속도를 가속 시키거나 7b가 아닌 13b모델의 구동이 가능합니다.
간단히 성능 비교를 위해 제 환경에서 구동했던 모델들의 성능지표입니다.
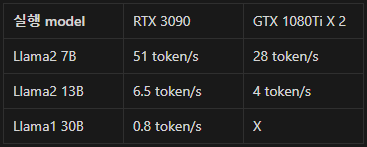 Llama1 30B 모델을 구동하기위해서 gpu-layer를 낮게조절하여 좋지않은 성능이 나온것도 있지만, 구동하는데 필요한 최소사양이 메모리 50GiB정도를 필요로 합니다.
Llama1 30B 모델을 구동하기위해서 gpu-layer를 낮게조절하여 좋지않은 성능이 나온것도 있지만, 구동하는데 필요한 최소사양이 메모리 50GiB정도를 필요로 합니다.
확실히 모델이 커지면 필요한 사양이 기하급수적으로 증가하네요.
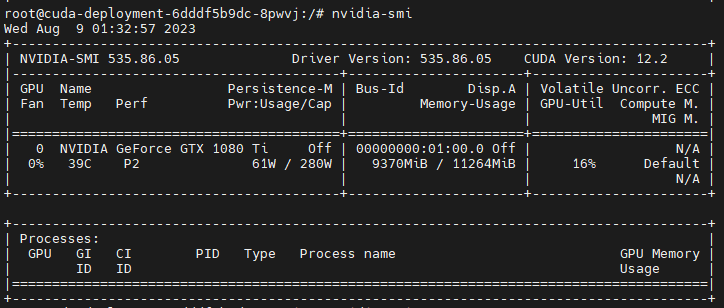
모델을 실행하면서 사용하는 자원을 확인해봤습니다.
정상적으로 vram과 소비전력을 확인 할 수 있었습니다.
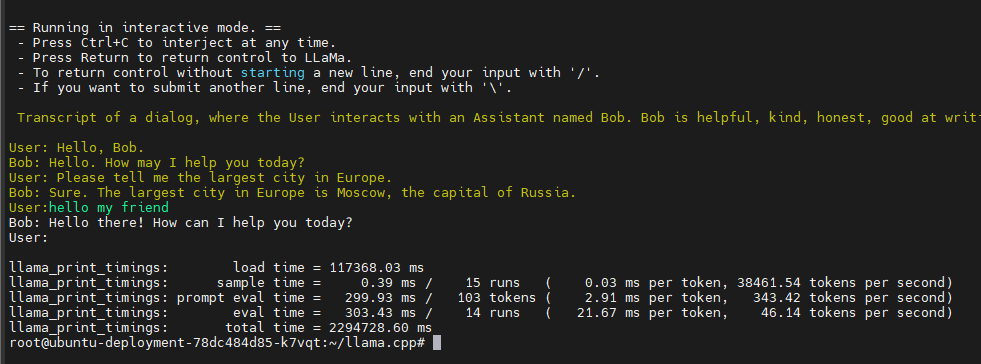
정상적으로 실행이 된다면 User : 항목에서 원하는 질문을 하며 대화를 할 수 있고
Ctrl + C 를 하면 대화를 종료 할 수 있습니다.
종료가 될 때 “tokens per second” 로 현재 실행 환경에서 연산 가능한 속도를 확인 할 수 있습니다.
이렇게 LLM을 위한 첫 발걸음을 내딛였습니다.
MLOPS가 될지, LLMOPS가 될지는 모르겠지만 오늘도 발전하는 하루였습니다.
다음번에는 새로운 것들을 들고와보겠습니다~