HPA 알아보기
July 2023 (1133 Words, 7 Minutes)
HPA 알아보기
오늘은 HPA에 대해 알아보는 시간을 갖겠습니다.
개념
Horizontal Pod Autoscaler는 쿠버네티스의 리소스 사용률에 따라 Pod의 수를 자동으로 조절하는 매커니즘입니다. HPA는 CPU 사용률 또는 사용자가 지정한 Custom 메트릭을 모니터링하여, 필요에 따라 Pod의 수를 늘리거나 줄이는 데 사용됩니다.
작동원리
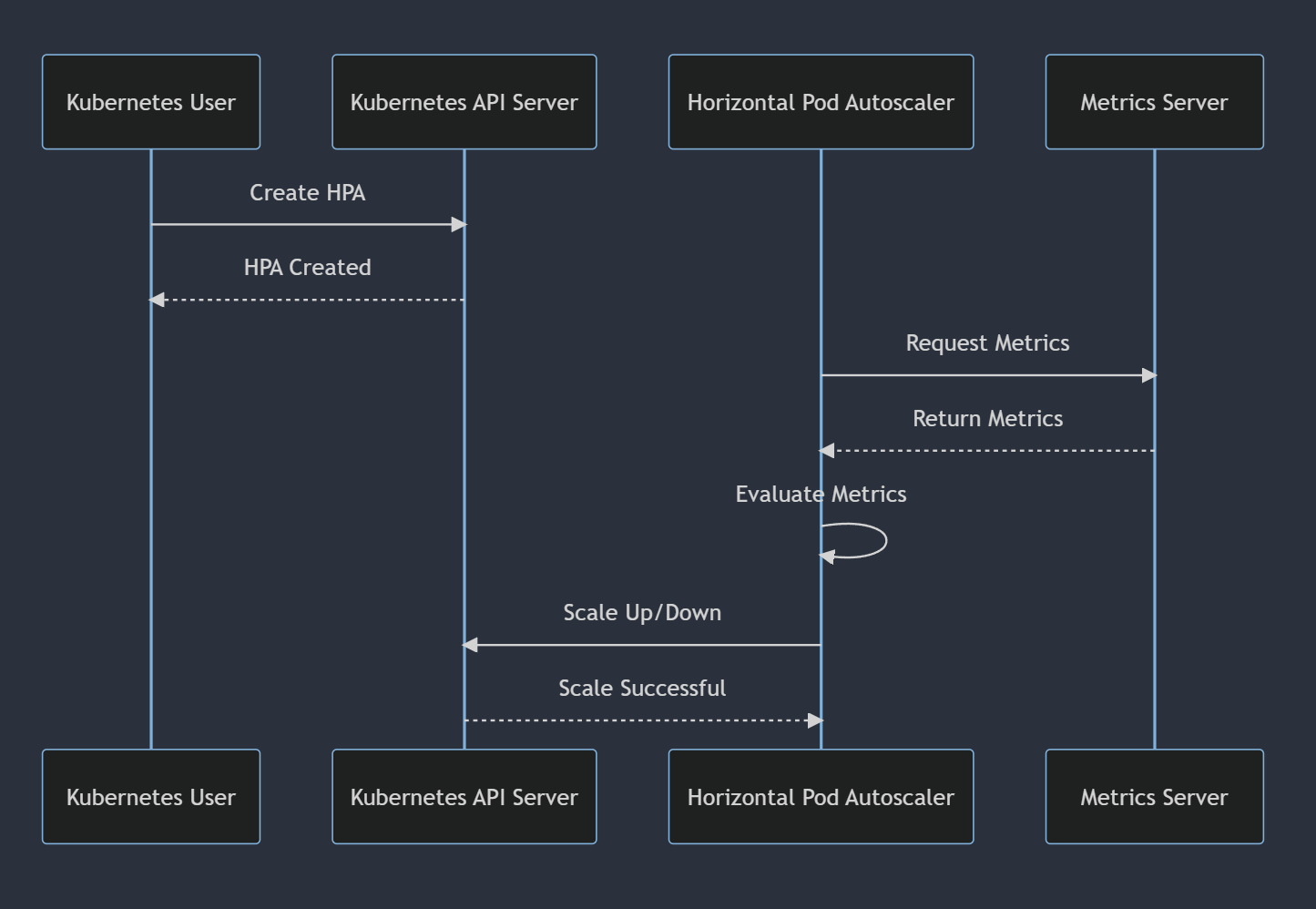
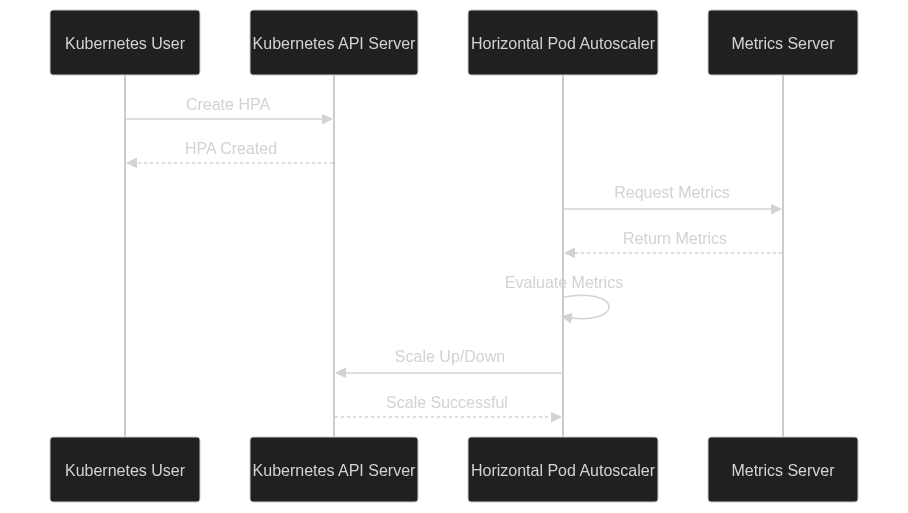
- 먼저, HPA는 주기적으로 모니터링 대상 메트릭을 체크합니다.
- 메트릭 값이 사용자가 지정한 임계값을 초과하면, HPA는 더 많은 Pod를 생성하여 부하를 분산시킵니다.
- 반대로, 메트릭 값이 지정된 임계값 이하로 떨어지면, HPA는 필요 없는 Pod를 종료하여 리소스를 절약합니다.
알고리즘 세부 정보
가장 기본적인 관점에서, HorizontalPodAutoscaler 컨트롤러는 원하는(desired) 메트릭 값과 현재(current) 메트릭 값 사이의 비율로 작동합니다.
원하는 레플리카 수 = ceil[현재 레플리카 수 * ( 현재 메트릭 값 / 원하는 메트릭 값 )]
설정방법
HPA를 설정하는 방법을 단계별로 설명하며, 이를 위해 필요한 쿠버네티스 매니페스트 파일의 예시를 제공합니다.
현재 블로그를 HPA로 Scaling 가능하게 전환하면서 사용한 Yaml파일은 다음과 같습니다.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: jekyll-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: jekyll-deployment
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
api version을 v1 기준으로 작성했던 hpa 파일입니다.
위의 HPA 구성에서는 scaleTargetRef를 통해 HPA가 적용되는 Deployment를 지정합니다. minReplicas와 maxReplicas는 Pod의 최소 및 최대 개수를 지정하며, targetCPUUtilizationPercentage는 HPA가 Pod를 확장하기 시작하는 CPU 사용률 임계값을 결정합니다. 이 경우, CPU 사용률이 50%를 넘으면 HPA는 Pod를 추가로 생성하는 알고리즘입니다.
Metrics
다만 apiVersion: autoscaling/v2가 출시되었기때문에, 새로 작성해봅니다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: jekyll-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: jekyll-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
targetCPUUtilizationPercentage으로 cpu 할당량을 구체적으로 설정할 수 있는 metrics 배열로 변경되었습니다. 아직은 CPU / 메모리 두개 밖에 사용이 불가능하지만, 추후에는 업데이트가 될 것 같은 생각이 드네요
metrics 에서는 type: Resource로 기존에 있던 targetCPUUtilizationPercentage 를 대체하는 기능 외에도 신규로 생성된 type이 있습니다.
1. 자원 메트릭에 대한 퍼센트 대신 값 지정
이 기능은 CPU와 같은 자원의 사용량에 대해 퍼센트 값을 사용하는 대신, 실제 값으로 명시할 수 있게 해줍니다. 더욱 세밀한 자원 사용률을 기반으로 HPA를 조정 가능해집니다.
예를 들어, 아래는 CPU 사용률을 값으로 명시한 HPA 설정의 예입니다:
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 200m
이 설정은 각 Pod가 평균적으로 200 mill의 CPU를 사용할 때까지 Pod의 수를 늘립니다.
2. 사용자 정의 메트릭
HPA에서 사용자 정의 메트릭을 지원하는 것은 매우 중요합니다. 이를 통해 애플리케이션에 특화된 메트릭에 기반하여 자동 스케일링을 수행할 수 있습니다. 두 가지 주요 사용자 정의 메트릭 타입이 있습니다: Pod 메트릭과 Object 메트릭.
- Pod 메트릭: 이는 각 Pod에 대한 메트릭을 설명합니다. 이 메트릭은 Pod 간의 평균을 내고, 그 평균값을 대상 값과 비교하여 레플리카 수를 조정합니다. 예를 들어, ‘packets-per-second’라는 메트릭이 있다면, 그 값을 특정 임계치와 비교하여 Pod의 수를 조절할 수 있습니다.
- Object 메트릭: 오브젝트 메트릭을 이용해 HPA를 구성할 때, 특정 오브젝트(예: Ingress, Service 등)의 메트릭을 이용합니다. 이는 ‘Value’ 또는 ‘AverageValue’ target 타입을 지원하며, 이들은 각각 API에서 반환된 메트릭 값을 직접적으로 비교하거나, 메트릭 값을 Pod의 수로 나눈 값을 대상 값과 비교하는 방식으로 동작합니다.
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
예를 들어, “requests-per-second”라는 오브젝트 메트릭이 있다고 가정해보겠습니다. 이 메트릭은 Ingress 오브젝트 ‘main-route’에 연관되어 있지만, 이 메트릭 값은 실제로는 해당 Ingress 오브젝트에 도달하는 트래픽의 요청 수를 나타냅니다. 이런 값은 일반적으로 로드 밸런서나 인그레스 컨트롤러 같은 외부 시스템에서 모니터링하고 수집합니다.
ingress 의 요청을 수집하려면 별도로 prometheus-adapter를 이용하여 ingress 관련 메트릭을 별도로 수집해야 합니다. 과정이 아주 간단하지 않기때문에, 위 방법은 별도의 문서에서 다뤄보도록 하겠습니다.
코드에 메트릭이 설정된 대상 값이 2k라는 것은, 초당 2000개의 요청이 이 Ingress 오브젝트에 도달했을 때, HPA가 스케일링을 수행하도록 설정되어 있다는 것을 의미합니다.
이 설정은, Ingress ‘main-route’에 도달하는 트래픽이 많아지면, 자동으로 더 많은 Pod를 생성하여 트래픽을 처리하도록 하기 위한 것입니다.
HPA는 이 설정을 보고 Kubernetes API 또는 외부 메트릭 시스템으로부터 해당 메트릭의 현재 값을 가져옵니다. 가져온 현재 메트릭 값과 설정된 대상 값을 비교하고, 필요에 따라 Pod의 수를 증가 또는 감소 시킵니다.
3. 커스텀 메트릭 블록
HPA는 여러 메트릭 블록을 포함할 수 있으며, 이를 통해 여러 메트릭을 기반으로 스케일링 결정을 내릴 수 있습니다. HPA는 각 메트릭에 대해 제안된 레플리카 수를 계산하고, 그중 가장 높은 레플리카 수를 선택합니다. 이를 통해 다양한 메트릭을 종합적으로 고려하여 더욱 정교한 스케일링 결정을 내릴 수 있습니다.
- type: External
external:
metric:
name: queue_messages_ready
selector:
matchLabels:
queue: "worker_tasks"
target:
type: AverageValue
averageValue: 30
CRD처럼 커스텀 메트릭에 의해 HPA 동작 조건을 설정할 수 있습니다.
message queue나 특정 상황의 아키텍처에서 서비스 개발을 할 때 고려해볼 만한 방식의 HPA 조건 설정입니다.
Behavior
autoscaling/v2 부터 (beta는 제외) behavior 필드라는것이 새로 생겼습니다.
스케일 업 동작 / 스케일 다운 동작을 별도로 구성할 수 있습니다.
우선 간단한 예제코드를 보면서 이해를 해보겠습니다.
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
periodSeconds 는 폴리시가 참(true)으로 유지되어야 하는 기간을 나타냅니다.
첫 번째는 (Pods)가 1분 내에 최대 4개의 Replicas를 스케일 다운할 수 있도록 허용하는 정책입니다.
두 번째는 현재 Replicas의 최대 10%를 1분 내에 스케일 다운할 수 있도록 허용하는 정책입니다.
이제 조금 더 종합적으로 여러가지 변수들을 담았습니다.
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max
behavior 섹션에는 scaleUp과 scaleDown 두 가지 하위 섹션이 있습니다.
scaleUp: 파드의 수를 늘리는 방식을 제어합니다.scaleDown: 파드의 수를 줄이는 방식을 제어합니다.
각 하위 섹션에는 다음과 같은 필드가 있습니다:
policies: 스케일링 정책을 정의하는 목록입니다. 정책은type,value,periodSeconds세 가지 필드로 구성됩니다.type:Pods또는Percent중 하나를 지정합니다.Pods는 정수의 수를,Percent는 현재 replica 수의 백분율을 나타냅니다.value: 스케일링 기간 동안 최대로 늘릴 수 있는 파드의 수를 나타냅니다.periodSeconds: 스케일링 정책이 적용되는 기간을 초 단위로 나타냅니다.
selectPolicy:Max,Min,Disabled중 하나를 선택합니다.Max는 주어진 시간 동안 가능한 최대 스케일링을,Min은 가능한 최소 스케일링을 나타냅니다.Disabled는 스케일링을 사용하지 않도록 설정합니다.stabilizationWindowSeconds: 스케일링 동작이 안정화되는 시간을 초 단위로 나타냅니다.
각 옵션에따라 조절한 스케일 전략을 미리 구성해둬서 최적화된 pod 확장을 구성해 둘 수 있습니다.
장단점
HPA를 사용하면 어떤 이점이 있는지, 그리고 어떤 상황에서는 주의해야 하는지 설명합니다.
실제 사례
제 블로그를 예시로 들면서 HPA의 실제 적용 사례를 살펴보겠습니다.
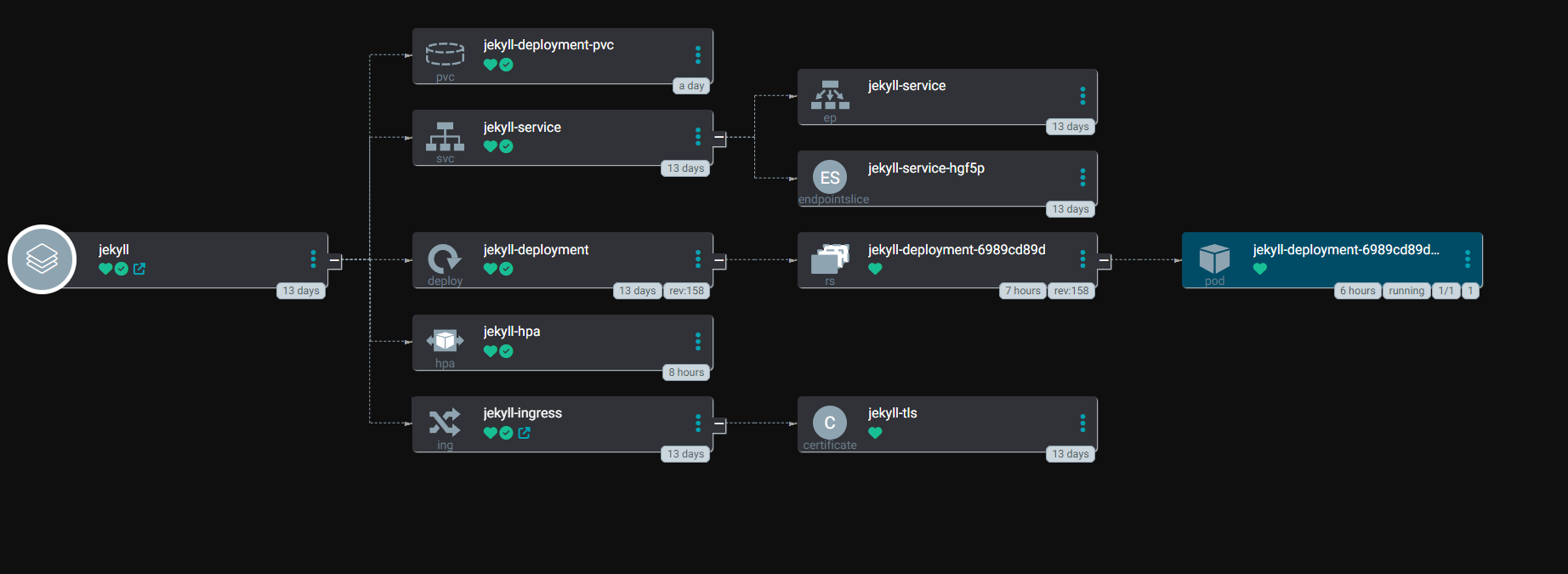
HPA 파일을 등록해둔 상태로 현재 이 블로그의 manifest들 배포 상태 입니다.
설정해둔 hpa 파일을 다음과 같습니다.
spec:
behavior:
scaleDown:
policies:
- periodSeconds: 60
type: Pods
value: 5
selectPolicy: Max
stabilizationWindowSeconds: 300
scaleUp:
policies:
- periodSeconds: 5
type: Percent
value: 100
- periodSeconds: 5
type: Pods
value: 5
selectPolicy: Max
stabilizationWindowSeconds: 0
maxReplicas: 30
metrics:
- resource:
name: cpu
target:
averageUtilization: 30
type: Utilization
type: Resource
minReplicas: 1
몇가지 scale up 기준들이 있고, 최대 30개까지 확장 가능하도록 구성해뒀습니다.

부하 테스트를 하기 전 minReplicas는 한개로 설정되어있어 현재 정상적으로 동작하는 상황입니다.
부하 테스트
부하 테스트는 종류가 다양하지만, 간단하게 명령어 한개로 테스트 가능한 방법을 선택했습니다.
hey -z 1m -c 200 http://blog.mont-kim.com
해당 명령어를 수행하게 되면 1분동안 200개의 요청이 병렬로 실행되며 저 도메인으로 요청을 생성합니다.
실제로 명령어를 수행하면서 hpa가 동작하는 것을 살펴보겠습니다
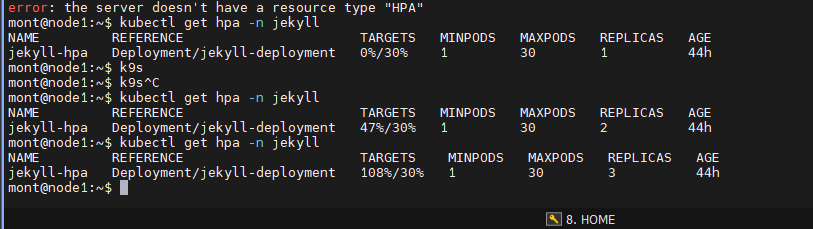
기준치 30%를 넘겨replicas를 점진적으로 증가시켜 pod를 생성하는 중입니다.
argocd에서도 증가된 pod들을 볼 수 있습니다.
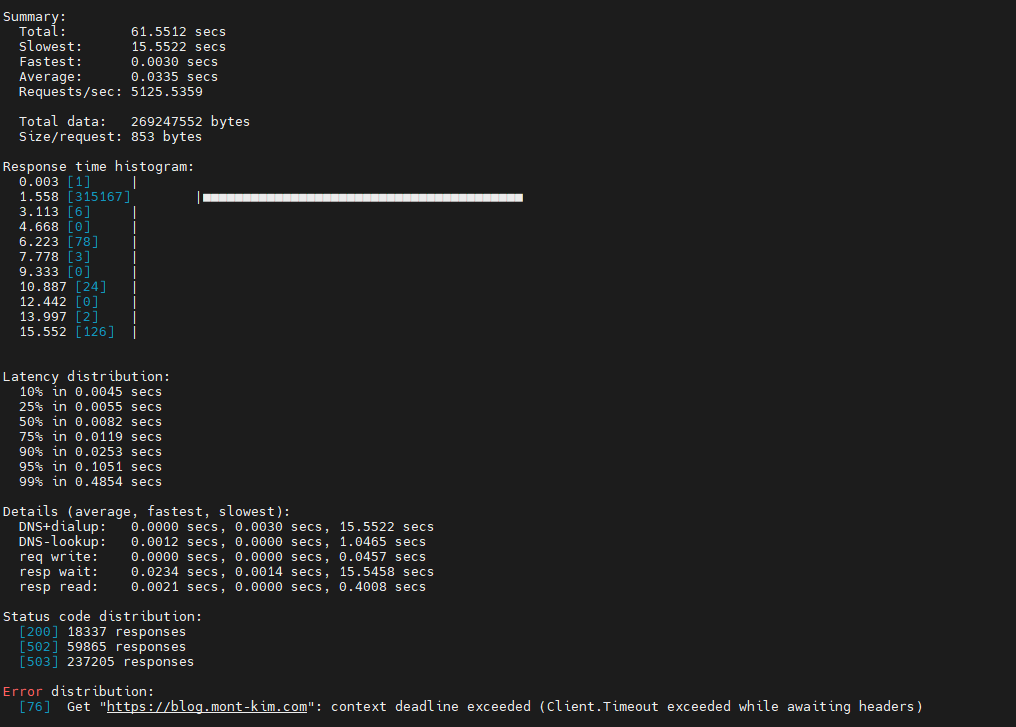
1분이라는 시간동안 hey 명령어로 얻은 결과물입니다.
76개의 요청에 대해서는 정상적으로 응답에 실패했지만, 많은 응답들이 정상적으로 수행되었고 99%의 응답은 0.5초 보다 적은 시간에 응답한 것을 확인했습니다.
완전 무결하게 모든 요청에대해 응답을 유연하게 하면서, 지연 시간도 줄이기 위해선 수많은 튜닝이 필요하지 않을까 싶네요.
이렇게 HPA 개념에 대해 알아보는시간, 그리고 설정하는 방법들을 알아보았습니다.