GPU 쪼개쓰기 (timeslicing)
June 2023 (721 Words, 5 Minutes)
GPU 쪼개쓰기 (time-slicing)
앞서 쿠버네티스에서 그래픽카드를 사용하는시간을 가졌다.
다만, 한개의 그래픽카드를 온전히 컨테이너 하나에 할당하는것은 꽤나 무거운 일일수도 있다.
간단하게 gpu에 대한 컨트롤을 하기위해 nvidia device-plugin을 설치했었는데
이번시간에는 device-plugin 보다 상위개념인 gpu-operator와 설치방법에 대해 다뤄보도록 한다.
GPU Operator
NVIDIA GPU Operator는 Kubernetes 클러스터 내의 NVIDIA GPU를 간편하게 관리하고 활용할 수 있게 돕는 소프트웨어입니다. 이는 Kubernetes의 Operator 패턴을 따르는데, 이 패턴은 특정 애플리케이션의 전체 수명주기를 관리하는 커스텀 리소스와 커스텀 컨트롤러를 사용합니다.
GPU Operator는 GPU 드라이버, CUDA 라이브러리, GPU 모니터링 도구 등 필요한 모든 컴포넌트를 Kubernetes에서 쉽게 배포하고 관리하는데 사용됩니다. 이 컴포넌트들은 컨테이너화되어 있어, 쿠버네티스 클러스터 어디에서든 쉽게 배포하고 실행할 수 있습니다.
다음은 GPU Operator가 관리하는 주요 컴포넌트들입니다:
- NVIDIA 드라이버: NVIDIA GPU를 사용하기 위해 필요한 기본 드라이버입니다. GPU Operator는 드라이버를 데몬셋(DaemonSet)으로 배포하여 클러스터의 각 노드에 설치합니다.
- NVIDIA Device Plugin: 쿠버네티스가 GPU 리소스를 인식하고 할당할 수 있게 돕는 플러그인입니다. 이 플러그인도 데몬셋으로 배포됩니다.
- NVIDIA DCGM (Data Center GPU Manager): GPU의 성능과 상태를 모니터링하는 도구입니다. DCGM exporter는 클러스터의 각 노드에 배포되어 Prometheus와 같은 모니터링 시스템에 GPU 메트릭을 제공합니다.
- NVIDIA Container Toolkit: GPU 지원을 필요로 하는 컨테이너를 실행하기 위한 도구입니다. 이는 각 노드의 Docker 또는 containerd 런타임과 통합됩니다.
GPU Operator를 사용하면, 이러한 컴포넌트들의 설치와 관리가 단순화되며, 따라서 GPU를 사용하는 워크로드의 배포와 스케일링이 더욱 쉬워집니다. 또한 GPU Operator는 NVIDIA Enterprise Support와 호환되어, 대규모 및 엔터프라이즈 환경에서의 GPU 사용을 지원합니다.
실제로 gpu operator를 설치하고나면, 새로운 device plugin이 설치되기도하고,
위 글을 작성하는 취지에 맞게, 쿠버네티스에서 관리하는 자원인 nvidia.com/gpu 리소스를 분할해 여러개로 관리하려고 한다면, 기존의 방식으로 사용하던 “그래픽카드 한장을 온전히 1로 할당” 해주는것과는 다르기에 기존의 device-plugin을 삭제 후 gpu operator만 설치를 진행해도 무방할것 같다.
CUDA 타임 슬라이싱으로 GPU를 공유하기 위해선 다음과 같은 문서를 참조한다.
Time-Slicing GPUs in Kubernetes — NVIDIA Cloud Native Technologies documentation
MIG(Multi-Instance GPU) 기능
타임슬라이싱은 아니지만 더 고차원적인 방법의 다중인스턴스 GPU MIG(Multi-Instance GPU)를 이용해 gpu를 분할하는 방법도 존재한다.
다만 이 기능의경우 A100, H100에서만 지원하는 기능이며 CUDA 애플리케이션을 위한 최대 7개의 별도 GPU 인스턴스로 안전하게 분할되어 여러 사용자에게 최적의 GPU 활용을 위한 별도의 GPU 리소스를 제공한다고 한다.
MIG Support in Kubernetes — NVIDIA Cloud Native Technologies documentation
다만 이 개념을 적용하기위해선 gpu-feature-discovery 설치를 선행해야한다.
GitHub - NVIDIA/gpu-feature-discovery: GPU plugin to the node feature discovery for Kubernetes
고객사의 GPU 클러스터 구축이 POC단계라 아직 A100 수준의 GPU 서버구성이 불가능한데, 추후에 진행한다면 같이 검토해볼만 할것같다.
설치
time slicing을 진행하기에 앞서 앞에서 이야기한 gpu operator의 설치가 선행되어야한다.
# GPU Operator를 설치하기 위한 Helm repo 추가
helm repo add nvidia https://nvidia.github.io/gpu-operator
# GPU Operator 설치
helm upgrade --install --wait gpu-operator nvidia/gpu-operator
설치가 진행되고나면, 해당 namespace에 생성되는 컴포넌트들은 다음과 같다.
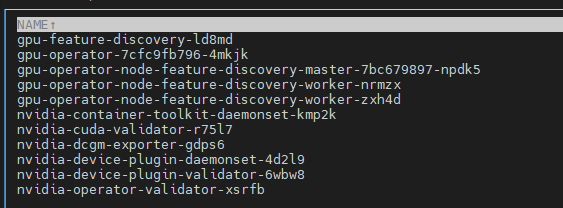
여기서도 다시끔 nvidia-device-plugin이 설치된것을 볼 수 있다.
gpu operator를 설치하고나면 기존에 존재하지않았던 clusterpolicy 라는 CRD(Custom Resource Definition)을 사용 할 수 있다.
time slicing을 어떻게 논리적으로 나눌지 정의하는 configmap 파일을 작성한다.
time-slicing-config-all.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-all
data:
any: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 4
파일 작성이 완료되었으면, configmap을 생성한다.
kubectl create -n gpu-operator -f time-slicing-config-all.yaml
mig 기능을 사용하는것은 아니고, gpu sharing 기능으로 gpu를 4개로 분할한 예시이다.
해당 configmap으로 device plugin을 구성하고, time slicing 설정을 적용한다.
kubectl patch clusterpolicy/cluster-policy \
-n gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config-all", "default": "any"}}}}'
해당 patch를 적용하고나면, gpu-feature-discovery, nvidia-device-plugin-daemonset pod가 다시 시작된다.
이후에 node describe 항목을 보면
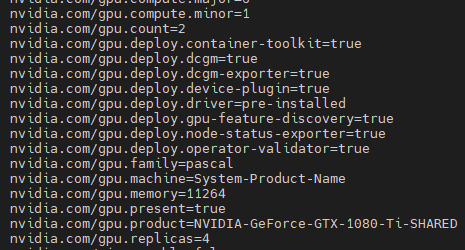
nvidia 관련된 항목들이 생긴것을 확인 할 수 있다.
해당 테스트를 진행한 환경은 1080ti가 2개 꽂혀있는 gpu 노드에서 진행되었으며
gpu.count=2 그래픽카드 두장이
gpu.replicas=4 한장을 4장씩 나누기때문에 총 8개의 자원을 할당할 수 있다.
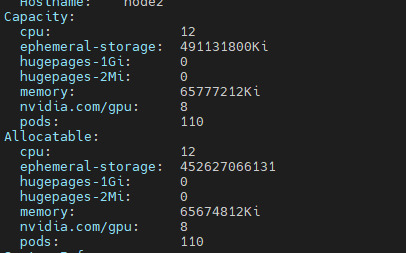
capacity와 allocatable 항목을 확인해도 2개였던 gpu가 8개로 분할된것을 확인 할 수 있다.
테스트 후 내린 결론
slicing 된 자원을 직접 확인할 방법은 없기때문에, ubuntu pod에서 “nividia-smi”명령어를 통해 몇개의 그래픽카드 자원을 조회하는 방식으로 확인을 진행했다.
2개의 그래픽카드를 8개로 분할해서 테스트를 진행했는데
그래픽카드를 각각 A,B 라고 했을때
A1 A2 A3 A4
B1 B2 B3 B4 이렇게 있다고 가정할때
pod-1 에 gpu를 5개 부여하면 필연적으로 그래픽카드 A의 4조각은 모두 쓰는것은 물론이고, B까지 사용할것이라고 예상을 했다. (A1, A2, A3, A4, B1) 사용
그러면 pod -2에 남은 gpu 3개를 부여하게되면, B1 B2 B3 의 조각을 사용하게된다면
nvidia-smi 명령어를 수행했을때 그래픽카드가 한개만 보여야하지만, A,B 그래픽카드 모두 조회할 수 있었다.
오히려 pod-2에 gpu를 2개만 부여했을때 nvidia-smi 명령어로 B 그래픽카드만 조회되는 상황임을 봤을때
time slicing 된 조각(분할된 nvidia/gpu 자원) 은 꽤나 무작위로 분할이되며 (A1 B1 A2 B3) 이런식
같은 종류의 분할된 time slicing 들은 구분이 안되는건지…
다른 종류의 그래픽카드를 분할한다면 조금 더 세분화 된 컨트롤이 가능할것같다.
1080ti 두장이 꽂힌 노드말고, 연산을 위해 준비한 3090이 달린 PC가 한대 더 있는데, ML 및 쿠버네티스에서의 GPU 사용에 대한 진도가 조금 더 진행되면 윈도우 → 리눅스로 변환해 더 세분화된 컨트롤을 진행할 것 같다.