GPU 노드 추가하기
June 2023 (339 Words, 2 Minutes)
홈 서버 클러트러링하기(2) GPU 노드 추가하기
그래픽 카드가 장착되어있는 노드를 쿠버네티스 클러스터에 join 한 이후에 필요한 작업이다.
기본적으로 장착한 그래픽 리소스를 사용하기위해선 그래픽 드라이버라고 말할 수 있는
nvidia-smi가 설치되어있어야 호스트에서 nvidia의 자원을 읽을 수 있다.
sudo apt update
apt search nvidia-driver
명령어를 통해 설치 가능한 버젼들을 확인한다.
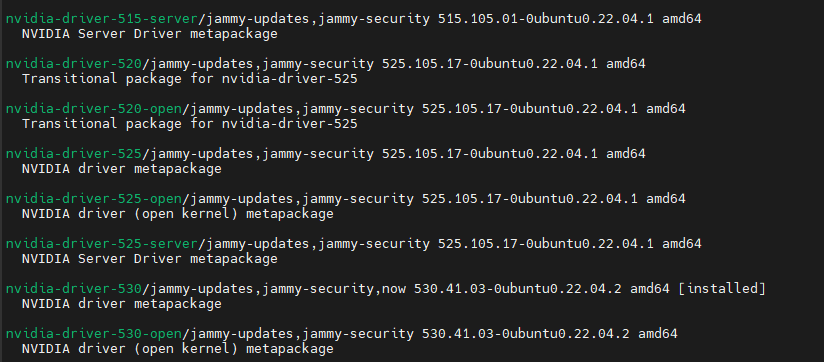
이중에서 현재 사용가능한 최신버젼인 nvidia-driver 항목중 최신버젼인 530버젼을 설치한다.
sudo apt install nvidia-driver-530
sudo reboot
설치 이후 재부팅을 진행해 nvidia 리소스를 읽을수 있는 상태로 만들어준다.
nvidia-smi
명령어를 수행해보면, 우분투에서 nvidia 자원을 사용하고있는지 확인을 할 수 있다.
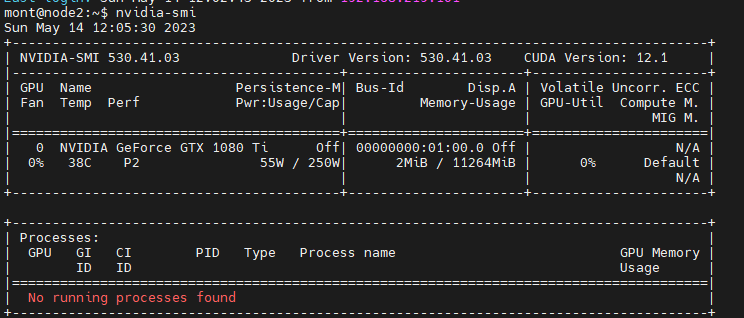
idle 상태인데 55W나 먹길래 HDMI 선을 뺴보니 10W로 줄어든다
상면비용까지 계산할필욘 없지만, 불필요한 전기를 사용할필요가 없으니 선은 빼주는게 좋을것같다.
컨테이너 환경에서도 nvidia 자원을 사용하려면 nvidia-docker를 설치해줘야한다.
curl -sL https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -sL https://nvidia.github.io/nvidia-docker/ubuntu22.04/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
gpg 키를 등록한후
sudo apt update
sudo apt install -y nvidia-docker2
설치를 진행해준다.
설치한후, 쿠버네티스에서 nvidia-docker를 설치하기위해선 컨테이너 런타임 설정파일을 변경해줘야한다.,
docker도 docker socket 파일을 변경해줘야하고
현재 쿠버네티스에서 사용하는 default 런타임은 containerd이기때문에, containerd의 설정파일을 변경해준다.
기존파일에 설정된게있어, 값을 수정한 최종형태를 담았다
vi /etc/containerd/config.toml
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
oom_score = 0
[grpc]
max_recv_message_size = 16777216
max_send_message_size = 16777216
[debug]
level = "info"
[metrics]
address = ""
grpc_histogram = false
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.k8s.io/pause:3.8"
max_container_log_line_size = -1
enable_unprivileged_ports = false
enable_unprivileged_icmp = false
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
runtime_engine = ""
runtime_root = ""
base_runtime_spec = "/etc/containerd/cri-base.json"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
systemdCgroup = true
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_type = "io.containerd.runc.v2"
runtime_engine = ""
runtime_root = ""
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://registry-1.docker.io"]
설정을 변형해준뒤 컨테이너D 런타임을 재시작한다
sudo systemctl restart containerd
이제 컨테이너 런타임에서 gpu를 사용이 가능할 뿐
쿠버네티스에서 자원을 자유자재로 관리할 수 있다는것은 아니기때문에
쿠버네티스에서 gpu 자원을 원활이 읽고쓰기위해선 device-plugin이라는 중계 장치가 필요하다.
wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.12.3/nvidia-device-plugin.yml
sudo kubectl apply -f nvidia-device-plugin.yml
쿠버네티스에서 제공하는 device plugin들은 각 제조사에 맞게 HW 자원을 쪼개 쓸 수 있게 만들어주는 역할을 한다. 엔비디아 디바이스 플러그인을 설치하자
생각보다 image pulling 시간이 꽤 걸린다.
네트워크 문제인지, 이미지가 큰건지
이제 테스트 pod으로 ubuntu pod을 만들어 pod 내에서 nvidia 자원을 읽을수 있는지 확인한다’
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-18.04
spec:
nodeName: node2
containers:
- name: os-ubuntu
image: ubuntu:20.04
imagePullPolicy: IfNotPresent
command:
- "/bin/sleep"
- "3650d"
resources:
limits:
cpu: "2"
memory: "8G"
nvidia.com/gpu: "1"
이런 yaml파일로 pod을 하나 생성한뒤 들어가서 확인해본다
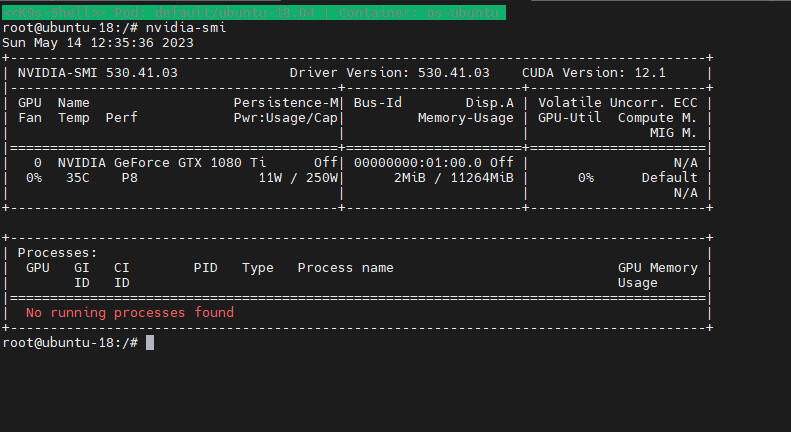
이렇게 정상적으로 자원이 할당되는것을 확인했다.
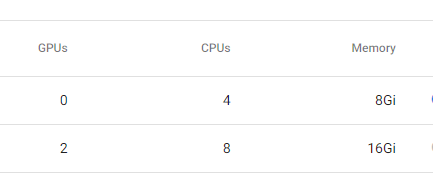
kubeflow에서도 gpu : 2 / 제조사 : nvidia 와 같은 명령어도 정상적으로 사용됨을 확인했다.
다만 쿠버네티스에서는 자원을 cpu / memory 로 관리를 한다.
gpu 갯수도 할당된만큼 쓸수있는데
https://kubernetes.io/ko/docs/tasks/manage-gpus/scheduling-gpus/
실제로 얼마나 잘라서 사용한다는건지 모르겠다…
추가적으로 gpu에서 사용하는 비디오램(vram)에 대한 자원할당은 쿠버네티스에서 직접적인 지원을 하지않는다.
따라서 custom resource로 할당해주는 자원이 얼마정도의 vram을 사용하는지 측정한뒤
custom resource로 관리하는 방법이 있다고 한다.
실제로 학습을 본격적으로 시작하게된다면, 그때 더 상세하게 다루어 봐야겠다.