컨테이너의 모든것
August 2024 (727 Words, 5 Minutes)
컨테이너 격리 🚧
리눅스 프로세스 격리 기술 발전
](/images/KANS/week1/part2/sch.png)
https://speakerdeck.com/kakao/ige-dwaeyo-dokeo-eobsi-keonteineo-mandeulgi?slide=200
시간이 지남에따라 저런 형태의 프로세스 격리기술들을 통해 완성된 리눅스 컨테이너는 다음과 같은 격리들을 갖고있습니다.
- Kernel namespaces
- IPC, UTS, mount, PID, network, user을 이용한 시스템 자원 격리
- Apparmor and SELinux profiles
- 보안 정책
- Seccomp policies
- 보안 정책2
- Chroots (using pivot_root)
- 파일 시스템을 격리하여 프로세스가 호스트 파일 시스템에 엑세스 방지
- Kernel capabilities
- 컨테이너의 프로세스 권한 제한
- CGroups (control groups)
- 리소스 사용량 제한 (CPU, 메모리, Disk I/O 등)
Docker도 결국 이런것들을 이용해 컨테이너 기술을 이용한것 뿐이며, Docker를 이용하지 않아도 컨테이너를 이용할 방법은 있습니다.
LXC를 이용한 컨테이너 만들기
sudo apt update
sudo apt install lxc lxc-templates
lxc-create -n mynginx -t download
lxc-create -n mynginx -t download -- --dist ubuntu --release focal --arch amd64
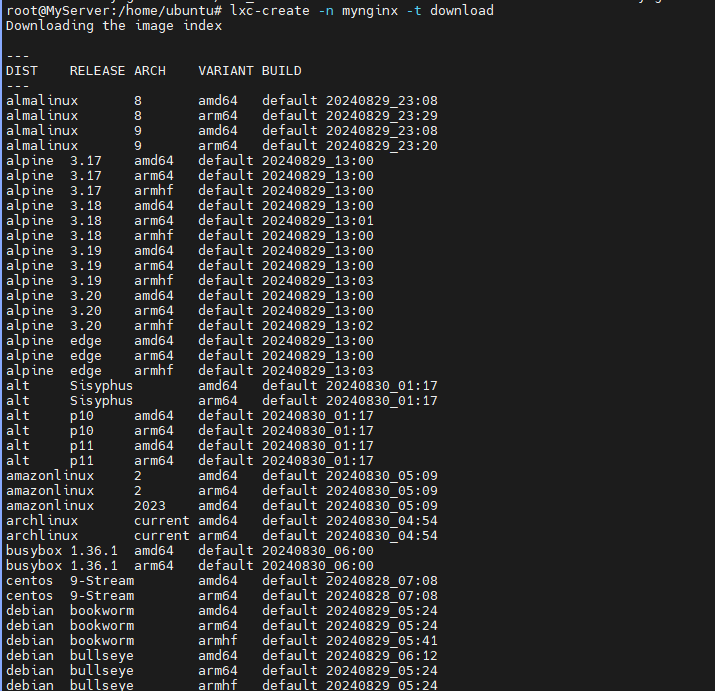
sudo lxd init
lxc launch ubuntu:22.04 mynginx
lxc info
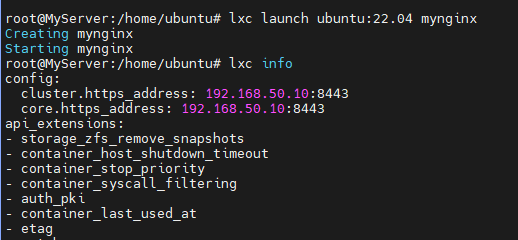
컨테이너로 들어가는 명령어는 다음과 같습니다.
lxc exec mynginx -- bash
lxc 명령어를 이용해 생성했던 컨테이너의 네트워크 바인딩을 직접 설정할수도 있습니다.
lxc config device add mynginx myport80 proxy listen=tcp:0.0.0.0:9000 connect=tcp:127.0.0.1:80
Cgroup의 자원격리
](/images/KANS/week1/part2/Untitled.png)
https://wizardzines.com/comics/cgroups/
cgroup은 컨테이너의 자원을 격리하는 기술입니다.
cgroup v1, v2가 존재하며 v2는 v1에 비해 자원계층구조의 가시성을 향상시켰습니다.
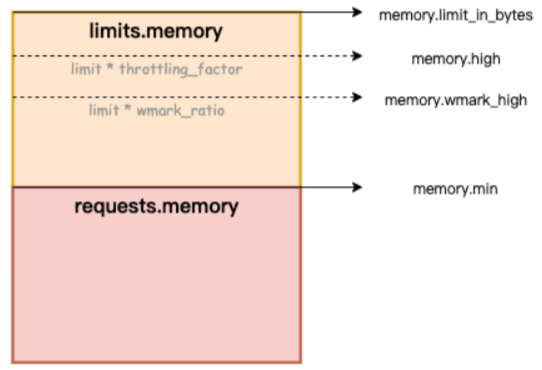
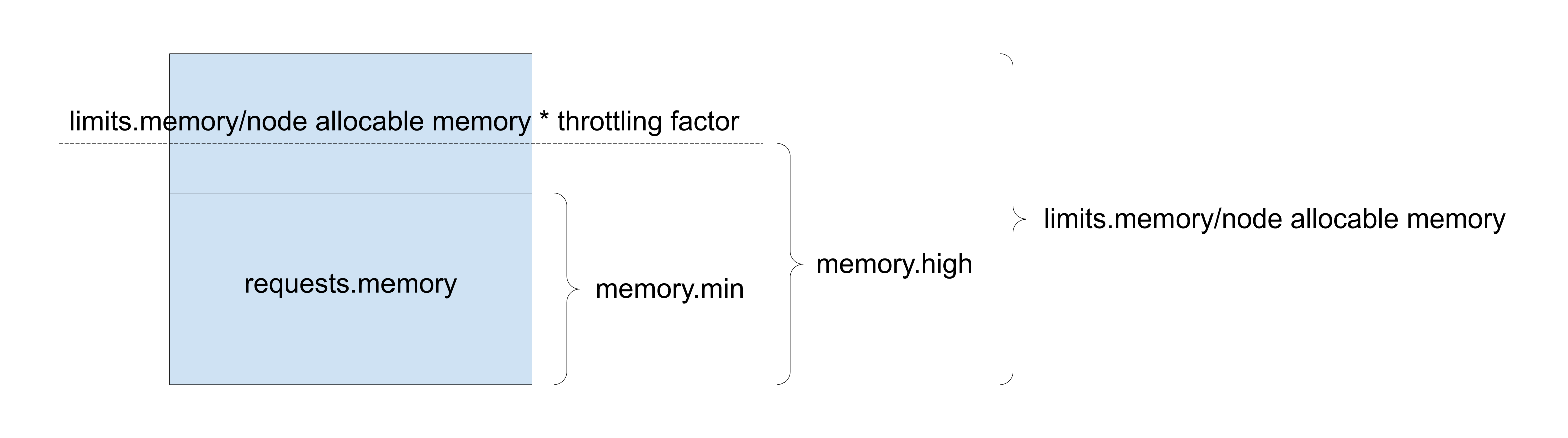
추가적으로 cgroup v1에서는 request, limit 두개의 자원설정만이 가능했는데, cgroup v2에서는 memoryQoS라는 기능을 추가하여 컨테이너 등에서 쉽사리 OOM이 나지않게 하는 기능들을 지원합니다.
Memory High : 메모리 사용량 조절 제한. cgroup의 사용량이 높은 경계를 초과하면 cgroup의 프로세스가 제한되고 회수 압력이 커집니다.
상한을 초과해도 OOM 킬러가 호출되지 않으며 극단적인 상황에서는 한도가 위반될 수 있습니다. 높은 제한은 과도한 회수 압력을 완화하기 위해 외부 프로세스가 제한된 cgroup을 모니터링하는 시나리오에서 사용해야 합니다.
memory.high Memory usage throttle limit. If a cgroup’s usage goes over the high boundary, the processes of the cgroup are throttled and put under heavy reclaim pressure. Going over the high limit never invokes the OOM killer and under extreme conditions the limit may be breached. The high limit should be used in scenarios where an external process monitors the limited cgroup to alleviate heavy reclaim pressure.

해당 그림에서는 cgorup memory high 를 1G로 설정해 특정수준 이상의 프로세스 생성을 방지합니다.
다음과같이 적용이 되기도하며 쿠버네티스에서도 feature gate 를 이용해 활성화 가능합니다.
아직은 1.22 이후로 alpha 를 유지중이며, 1.27 에서 일부 로직의 개선이 있었지만 아직 완성형에 닿기엔 부족한 부분이 많은것같습니다.
컨테이너 내부에서는 /sys/fs/cgroup 하위에 있는 값들을 통해 현재 컨테이너에서 사용 가능한 cpu, memory 의 사용량을 계산 할 수 있습니다.
Cgroup에서의 CPU 자원 공유
cgroup에서 보장해주는 cpu time은
Linux Kernel의 cgroup을 이용하여 리소스를 제한합니다.
CFS(Completely Fair Scheduler) Quota를 이용하여 CPU time share를 할당받습니다.
CPU Time = NumCPUs ∗ shares / ∑shares
공식을 따릅니다.
CFS Bandwith Control 을 해주는 두가지 변수가있습니다
cfs_quota_us와 cfs_period_us는 리눅스 커널의 Completely Fair Scheduler (CFS)에서 사용하는 설정값들로, 컨테이너나 프로세스 그룹에 CPU 시간의 할당을 제한하는 데 사용됩니다.
cfs_period_us : CFS 대역폭 제어의 accounting 기간을 나타냅니다. 즉, CPU 사용량은 이 기간 동안 측정되고 제한됩니다.
태스크 그룹의 CPU 사용량을 통제할 주기(period)를 정의
cfs_quota_us : 각 CFS accounting 기간 동안 프로세스 그룹이 사용할 수 있는 CPU 시간의 최대량을 나타냅니다.
재밌게도 Request 와 Limit 설정은, 이러한 CFS 알고리즘에 의한 시간분배를 방해하는 요소가 되기도하는데
https://github.com/torvalds/linux/commit/f4183717b370ad28dd0c0d74760142b20e6e7931
다음 글을 읽어보시면 흥미롭습니다.
Resource_Triggeric61ng_Throttling
Cgroup V1 기준으로 리눅스 커널 5.14부터 CPU Burst 라는 기능이 추가되어 Throttling이 덜 한 CPU Sharing 을 보정할 수 있게 해주지만, 쿠버네티스는 그닥 관심을 보이지 않는듯 합니다.
오히려 alibaba cloud 쪽의 기술블로그 와 오픈소스들에서 이런곳에서의 더 큰 관심사들을 보이고, Kubernetes 에 기여하고자 하는바가 크지만 거절된 PR들이 몇개 보입니다.
3부작 글을 읽고오면 조금 더 이해가 잘 되실것 같습니다.
해당 글에서 기고했던 2021 Kubecon CHINA 발표자료인데 같이 보시면 흥미롭습니다.
그래도 이러한 쓰로틀링은 아직 남아있을수 있지만, 조금은 다른 방법의 “온전한 자원할당” 방법이 하나 더 있습니다
CPU 고정코어 할당하기
CFS 알고리즘을 통해 8코어 호스트 에서 2코어의 Container를 만들경우
2 * 1000 만큼의 cpu time share를 보장받습니다. (그리고 8개의 코어에서 2/8 * 1000만큼 쓰겠죠)
하지만 이는 코어 8개에서 적절히 돌아가기때문에 매번 cpu context switching이 이루어지고 굉장한 비 효율을 가져옵니다.
이를 위해 나온기능은 고정 CPU 코어 할당입니다.
container runtime에서 직접 제공하는 기능들이며, 고정코어를 온전히 분리하여,
2코어를 온전한 컨테이너를 위한 할당을 하면
나머지 컨테이너들은 6코어를 나눠쓰는 개념을 말합니다.
kubernetes 공식 document에 있는 이미지를 이미지번역기를 돌려봤습니다.
이 개념이 자리잡은지 얼마 안되었을때 intel에서 제공했던 벤치마크 자료에서 조금은 유의미한 성능지표를 모니터링 할 수 있습니다.
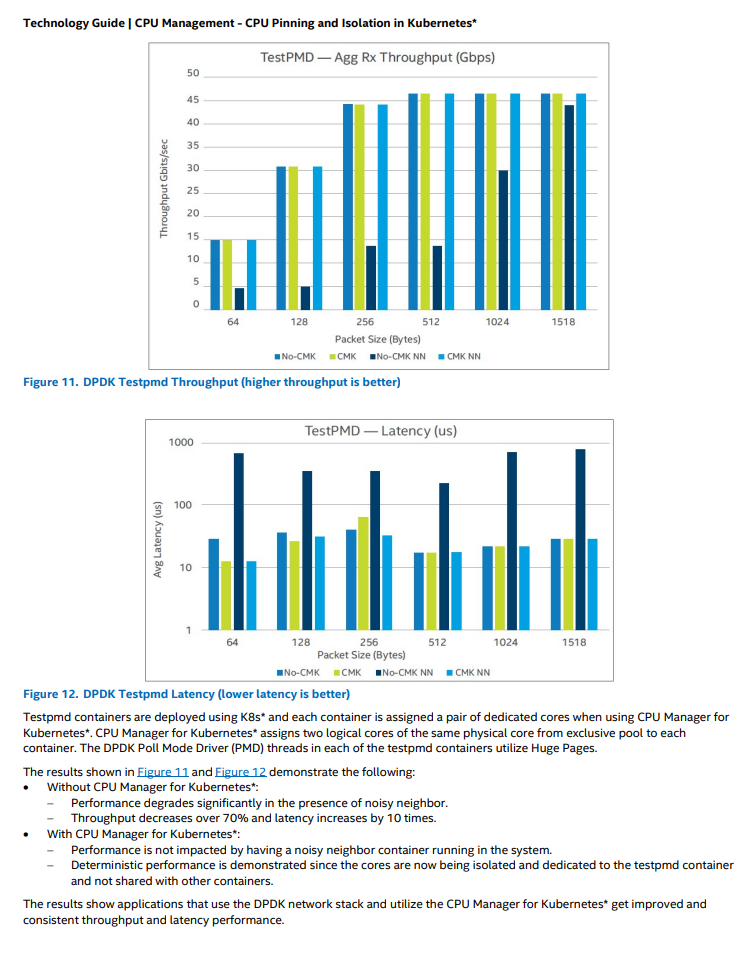
CMK NN → Cpu 고정할당을 하고, Noisy Neighbor 상황 (노드에 다른 작업들이 공존하는경우) 에서 그렇지 않을때와 비교하면 유의미한 레이턴시 차이가 나온다고 합니다.
Linux Container File System…
시간되면 다룬다….